In a microservices architecture, services depend on each other through network calls. When one service fails or slows down, that failure can cascade through the system, bringing down services that were otherwise healthy. This is where circuit breakers and resilience patterns become essential.
These patterns help services handle failures gracefully, reduce downtime, and maintain system stability even when individual components fail. Understanding and implementing them correctly is crucial for building production-ready distributed systems.
This post explains what circuit breakers are, how they work, and how to combine them with other resilience patterns for comprehensive fault tolerance in microservices.
What Is a Circuit Breaker?
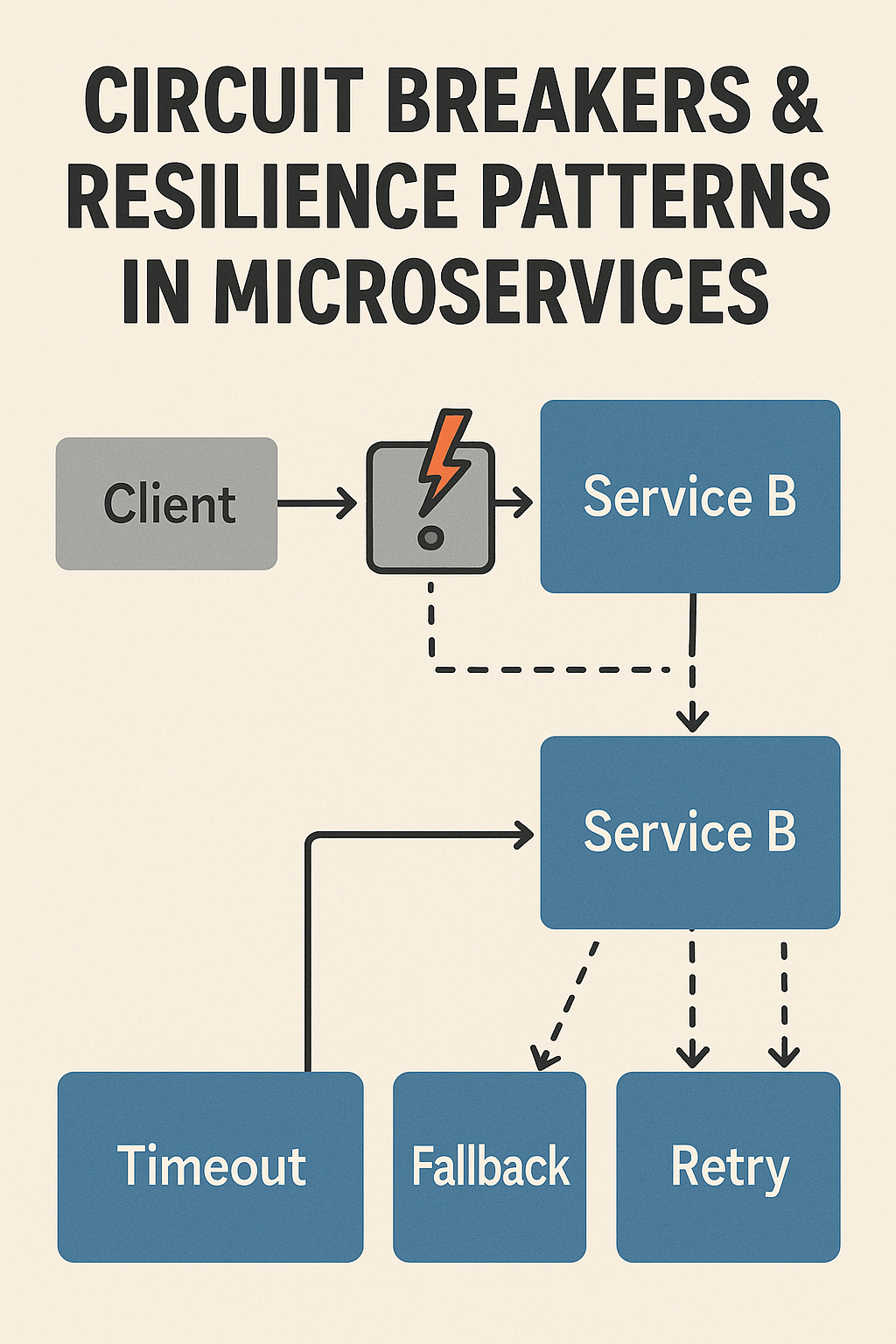
A circuit breaker is a design pattern that prevents an application from repeatedly trying to execute an operation that’s likely to fail. Like an electrical circuit breaker that trips to prevent damage, a software circuit breaker “opens” when failures exceed a threshold, stopping requests to a failing service.
Circuit Breaker States
Circuit breakers operate in three states:
Closed State: Normal operation. Requests flow through to the downstream service. The circuit breaker monitors for failures.
Open State: After failures exceed the configured threshold, the circuit breaker opens. All requests fail immediately without attempting to call the downstream service. This prevents resource exhaustion and gives the failing service time to recover.
Half-Open State: After a configured timeout, the circuit breaker allows a limited number of test requests through. If these succeed, the circuit closes. If they fail, the circuit reopens.
// Circuit breaker state transitions
CLOSED ──[failures exceed threshold]──► OPEN
▲ │
│ │
│ [timeout expires]
│ │
│ ▼
└──[test requests succeed]────── HALF-OPEN
│
[test requests fail]────┘
Why Circuit Breakers Matter
Without circuit breakers, a slow or failing service causes problems throughout your system:
- Thread exhaustion: Requests waiting for timeouts consume threads that could serve healthy requests
- Cascading failures: Service A waiting on Service B causes Service C waiting on Service A to fail
- Resource starvation: Connection pools fill up with connections to failing services
- Poor user experience: Users wait for long timeouts instead of getting fast failures
Circuit breakers address all of these by failing fast when a service is known to be unhealthy.
Implementing Circuit Breakers
Let’s examine practical implementations using popular libraries.
Resilience4j (Java/Spring)
Resilience4j is the modern standard for resilience in Java applications:
import io.github.resilience4j.circuitbreaker.CircuitBreaker;
import io.github.resilience4j.circuitbreaker.CircuitBreakerConfig;
import io.github.resilience4j.circuitbreaker.CircuitBreakerRegistry;
import java.time.Duration;
public class PaymentService {
private final CircuitBreaker circuitBreaker;
private final PaymentGateway paymentGateway;
public PaymentService(PaymentGateway paymentGateway) {
this.paymentGateway = paymentGateway;
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // Open after 50% failures
.waitDurationInOpenState(Duration.ofSeconds(30)) // Wait before half-open
.slidingWindowSize(10) // Evaluate last 10 calls
.minimumNumberOfCalls(5) // Need 5 calls before evaluating
.permittedNumberOfCallsInHalfOpenState(3) // Test with 3 calls
.build();
CircuitBreakerRegistry registry = CircuitBreakerRegistry.of(config);
this.circuitBreaker = registry.circuitBreaker("paymentGateway");
}
public PaymentResult processPayment(PaymentRequest request) {
return circuitBreaker.executeSupplier(() ->
paymentGateway.charge(request)
);
}
}
With Spring Boot, you can use annotations for cleaner code:
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import org.springframework.stereotype.Service;
@Service
public class InventoryService {
private final InventoryClient inventoryClient;
@CircuitBreaker(name = "inventory", fallbackMethod = "getInventoryFallback")
public InventoryStatus checkInventory(String productId) {
return inventoryClient.getStatus(productId);
}
// Fallback returns cached or default data
private InventoryStatus getInventoryFallback(String productId, Exception e) {
log.warn("Circuit breaker fallback for product {}: {}", productId, e.getMessage());
return InventoryStatus.unknown(productId);
}
}
Polly (.NET)
Polly provides resilience patterns for .NET applications:
using Polly;
using Polly.CircuitBreaker;
public class OrderService
{
private readonly AsyncCircuitBreakerPolicy _circuitBreaker;
private readonly IPaymentClient _paymentClient;
public OrderService(IPaymentClient paymentClient)
{
_paymentClient = paymentClient;
_circuitBreaker = Policy
.Handle<HttpRequestException>()
.Or<TimeoutException>()
.CircuitBreakerAsync(
exceptionsAllowedBeforeBreaking: 3,
durationOfBreak: TimeSpan.FromSeconds(30),
onBreak: (exception, duration) =>
{
Log.Warning("Circuit opened for {Duration}s: {Message}",
duration.TotalSeconds, exception.Message);
},
onReset: () => Log.Information("Circuit closed"),
onHalfOpen: () => Log.Information("Circuit half-open")
);
}
public async Task<PaymentResult> ProcessPaymentAsync(PaymentRequest request)
{
return await _circuitBreaker.ExecuteAsync(async () =>
await _paymentClient.ChargeAsync(request)
);
}
}
Node.js Implementation
For Node.js, libraries like opossum provide circuit breaker functionality:
const CircuitBreaker = require('opossum');
class PaymentService {
constructor(paymentClient) {
this.paymentClient = paymentClient;
const options = {
timeout: 3000, // Call timeout
errorThresholdPercentage: 50, // Open at 50% failures
resetTimeout: 30000, // Try again after 30s
volumeThreshold: 5 // Minimum calls before evaluating
};
this.breaker = new CircuitBreaker(
(request) => this.paymentClient.charge(request),
options
);
// Event handlers for monitoring
this.breaker.on('open', () =>
console.log('Circuit opened - payment gateway unavailable'));
this.breaker.on('halfOpen', () =>
console.log('Circuit half-open - testing payment gateway'));
this.breaker.on('close', () =>
console.log('Circuit closed - payment gateway recovered'));
this.breaker.on('fallback', (result) =>
console.log('Fallback called', result));
}
async processPayment(request) {
try {
return await this.breaker.fire(request);
} catch (error) {
if (error.message === 'Breaker is open') {
// Return fallback response
return { status: 'pending', message: 'Payment queued for retry' };
}
throw error;
}
}
}
Complementary Resilience Patterns
Circuit breakers work best when combined with other resilience patterns. Each pattern addresses different failure scenarios.
Retry with Exponential Backoff
Automatically retry failed requests with increasing delays between attempts. This handles transient failures without overwhelming recovering services.
// Resilience4j: Combining retry with circuit breaker
import io.github.resilience4j.retry.Retry;
import io.github.resilience4j.retry.RetryConfig;
RetryConfig retryConfig = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.exponentialBackoffMultiplier(2) // 500ms, 1000ms, 2000ms
.retryExceptions(IOException.class, TimeoutException.class)
.ignoreExceptions(BusinessException.class) // Don't retry business errors
.build();
Retry retry = Retry.of("paymentRetry", retryConfig);
// Compose: Retry wraps CircuitBreaker
// Retries happen within the circuit breaker's monitoring
Supplier<PaymentResult> decorated = Retry.decorateSupplier(
retry,
CircuitBreaker.decorateSupplier(circuitBreaker,
() -> paymentGateway.charge(request))
);
Key considerations:
- Don’t retry non-idempotent operations without safeguards
- Add jitter to prevent thundering herd on recovery
- Set maximum retry limits to avoid infinite loops
- Retry only transient failures, not business logic errors
Bulkhead Pattern
Isolate resources so one failing service can’t consume all available capacity. Named after ship bulkheads that contain flooding to one compartment.
// Resilience4j Bulkhead configuration
import io.github.resilience4j.bulkhead.Bulkhead;
import io.github.resilience4j.bulkhead.BulkheadConfig;
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(10) // Max 10 concurrent calls
.maxWaitDuration(Duration.ofMillis(500)) // Wait up to 500ms for slot
.build();
Bulkhead bulkhead = Bulkhead.of("paymentBulkhead", bulkheadConfig);
// Thread pool bulkhead for complete isolation
ThreadPoolBulkheadConfig threadConfig = ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(10)
.coreThreadPoolSize(5)
.queueCapacity(20)
.build();
ThreadPoolBulkhead threadPoolBulkhead =
ThreadPoolBulkhead.of("paymentPool", threadConfig);
Use cases:
- Separate thread pools for critical vs non-critical services
- Limit connections to specific external dependencies
- Prevent slow services from blocking fast ones
Fallback Strategies
Provide alternative responses when the primary service is unavailable. Good fallbacks maintain partial functionality rather than complete failure.
@Service
public class ProductService {
private final ProductClient productClient;
private final ProductCache productCache;
@CircuitBreaker(name = "products", fallbackMethod = "getProductFallback")
public Product getProduct(String productId) {
Product product = productClient.fetchProduct(productId);
productCache.store(product); // Update cache on success
return product;
}
// Fallback strategy: serve from cache
private Product getProductFallback(String productId, Exception e) {
log.warn("Using cached product for {}", productId);
return productCache.get(productId)
.map(cached -> {
cached.setFromCache(true); // Flag for UI
return cached;
})
.orElseGet(() -> Product.unavailable(productId));
}
}
Fallback options by scenario:
- Cached data: Return stale but valid data from cache
- Default values: Return safe defaults when possible
- Degraded functionality: Disable non-essential features
- Queue for later: Accept request and process when service recovers
Timeout Configuration
Timeouts prevent requests from waiting indefinitely. They’re essential for fast failure detection.
// Configure timeouts at multiple levels
// HTTP client timeout
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(2))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.payment.com/charge"))
.timeout(Duration.ofSeconds(5)) // Request timeout
.build();
// Resilience4j TimeLimiter
TimeLimiterConfig timeLimiterConfig = TimeLimiterConfig.custom()
.timeoutDuration(Duration.ofSeconds(3))
.cancelRunningFuture(true)
.build();
TimeLimiter timeLimiter = TimeLimiter.of(timeLimiterConfig);
Timeout guidelines:
- Set timeouts shorter than user patience threshold
- Consider downstream service SLAs
- Account for retry delays in total timeout budget
- Monitor timeout rates to detect degradation early
Rate Limiting
Limit incoming request rates to prevent overload. Rate limiting protects your service from being overwhelmed by upstream demand.
// Resilience4j RateLimiter
import io.github.resilience4j.ratelimiter.RateLimiter;
import io.github.resilience4j.ratelimiter.RateLimiterConfig;
RateLimiterConfig rateLimiterConfig = RateLimiterConfig.custom()
.limitForPeriod(100) // 100 calls per period
.limitRefreshPeriod(Duration.ofSeconds(1)) // Period = 1 second
.timeoutDuration(Duration.ofMillis(500)) // Wait up to 500ms
.build();
RateLimiter rateLimiter = RateLimiter.of("apiRateLimiter", rateLimiterConfig);
// Apply to endpoint
public Response handleRequest(Request request) {
return RateLimiter.decorateSupplier(rateLimiter,
() -> processRequest(request)
).get();
}
Combining Patterns Effectively
The order in which you apply resilience patterns matters. A typical composition:
// Recommended pattern composition order (outside to inside):
// RateLimiter -> TimeLimiter -> Bulkhead -> CircuitBreaker -> Retry -> Actual Call
@Service
public class ResilientPaymentService {
@RateLimiter(name = "payment") // 1. Rate limit incoming requests
@TimeLimiter(name = "payment") // 2. Enforce overall timeout
@Bulkhead(name = "payment") // 3. Limit concurrent calls
@CircuitBreaker(name = "payment", fallbackMethod = "fallback") // 4. Circuit breaker
@Retry(name = "payment") // 5. Retry transient failures
public CompletableFuture<PaymentResult> processPayment(PaymentRequest request) {
return CompletableFuture.supplyAsync(() ->
paymentGateway.charge(request)
);
}
private CompletableFuture<PaymentResult> fallback(PaymentRequest request, Exception e) {
return CompletableFuture.completedFuture(
PaymentResult.queued(request.getId())
);
}
}
Monitoring and Observability
Resilience patterns require monitoring to be effective. You need visibility into:
- Circuit breaker state changes: When circuits open and close
- Failure rates: What’s triggering circuit breakers
- Retry counts: How many retries are occurring
- Fallback usage: How often fallbacks are serving requests
- Timeout rates: How many requests are timing out
// Expose metrics for Prometheus/Grafana
@Configuration
public class ResilienceMetricsConfig {
@Bean
public MeterRegistryCustomizer<MeterRegistry> metricsCustomizer(
CircuitBreakerRegistry circuitBreakerRegistry,
RetryRegistry retryRegistry) {
return registry -> {
TaggedCircuitBreakerMetrics
.ofCircuitBreakerRegistry(circuitBreakerRegistry)
.bindTo(registry);
TaggedRetryMetrics
.ofRetryRegistry(retryRegistry)
.bindTo(registry);
};
}
}
Common Mistakes to Avoid
Setting thresholds too high: If your circuit breaker requires 90% failures to open, healthy services will be impacted before the circuit trips.
Ignoring half-open behavior: Too many test requests in half-open state can overwhelm a recovering service. Keep test traffic minimal.
Retrying non-idempotent operations: Retrying a payment charge without idempotency keys can result in double charges.
No fallback strategy: Circuit breakers without fallbacks just fail faster—which is better than hanging, but not as good as degraded functionality.
Static configuration: Optimal thresholds vary by service and load. Consider dynamic configuration based on observed behavior.
Conclusion
Resilience is not about avoiding failures—it’s about handling them gracefully. Circuit breakers and resilience patterns make microservices more reliable, protect user experience, and maintain system stability under stress.
Start with circuit breakers for your most critical dependencies, then add retry, bulkhead, and fallback patterns as needed. Monitor everything so you can tune thresholds based on real behavior rather than guesses.
For more on building reliable distributed systems, see Designing Event-Driven Microservices with Kafka. You can also explore the official Resilience4j documentation to learn implementation details for Java-based microservices.

1 Comment