Introduction
Developer documentation is critical, but searching through hundreds of pages of API references, tutorials, and wikis can be frustrating. Developers often spend more time finding the right documentation than actually implementing features. A chatbot powered by open-source LLMs provides a faster, more intuitive way to access documentation.
Instead of reading entire docs, developers can ask questions in natural language and receive context-aware answers instantly. Companies like Stripe, MongoDB, and Supabase have implemented documentation chatbots, seeing significant improvements in developer onboarding time and reduced support ticket volume.
In this comprehensive guide, we’ll build a complete documentation chatbot using open-source large language models, covering architecture design, implementation details, and production deployment strategies.
Why Use Open-Source LLMs?
While proprietary models like GPT-4 or Claude are powerful, open-source LLMs offer unique advantages for documentation chatbots:
- Privacy control: Run the model locally or on your own infrastructure—sensitive internal docs never leave your network
- Customization: Fine-tune on your team’s documentation, coding style, and domain terminology
- Cost efficiency: Avoid recurring API fees that scale with usage
- Transparency: Full access to model architecture, weights, and training decisions
- Latency control: Self-hosted models can provide faster response times for high-volume use cases
Popular options include Llama 3, Mistral, Mixtral, and Qwen, which can be hosted with libraries like Hugging Face Transformers, Ollama, or vLLM.
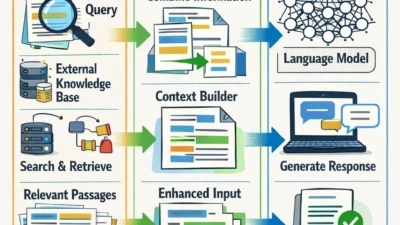
System Architecture
A documentation chatbot uses Retrieval-Augmented Generation (RAG) to provide accurate, contextual answers:
// Architecture overview
┌─────────────────────────────────────────────────────────────────┐
│ Documentation Chatbot │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────────┐ ┌──────────────────────┐ │
│ │ User │───▶│ Chat UI │───▶│ Query Processor │ │
│ │ Query │ │ (Next.js) │ │ (Reformulation) │ │
│ └──────────┘ └──────────────┘ └──────────┬───────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ RAG Pipeline │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌────────────────┐ │ │
│ │ │ Embedding │──▶│ Vector │──▶│ Retriever │ │ │
│ │ │ Model │ │ Store │ │ (Top-K docs) │ │ │
│ │ └─────────────┘ └─────────────┘ └───────┬────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌────────────────┐ │ │
│ │ │ Response │◀──│ Open-Source│◀──│ Reranker │ │ │
│ │ │ Generator │ │ LLM │ │ (Optional) │ │ │
│ │ └─────────────┘ └─────────────┘ └────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘Step 1: Collect and Prepare Documentation
Gather all documentation sources and convert them into a consistent format:
# src/ingestion/doc_loader.py
import os
import re
from pathlib import Path
from typing import List, Dict, Any
from dataclasses import dataclass
import markdown
from bs4 import BeautifulSoup
import yaml
@dataclass
class Document:
"""Represents a documentation chunk"""
content: str
metadata: Dict[str, Any]
source: str
doc_type: str # 'api', 'guide', 'tutorial', 'readme'
class DocumentationLoader:
"""Load and process documentation from multiple sources"""
def __init__(self, docs_path: str):
self.docs_path = Path(docs_path)
self.documents: List[Document] = []
def load_all(self) -> List[Document]:
"""Load all documentation files"""
# Load Markdown files
for md_file in self.docs_path.rglob("*.md"):
self.documents.extend(self._load_markdown(md_file))
# Load OpenAPI specs
for spec_file in self.docs_path.rglob("openapi*.yaml"):
self.documents.extend(self._load_openapi(spec_file))
# Load code examples
for code_file in self.docs_path.rglob("examples/**/*.py"):
self.documents.extend(self._load_code_example(code_file))
return self.documents
def _load_markdown(self, file_path: Path) -> List[Document]:
"""Load and chunk markdown files"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# Extract frontmatter
metadata = {}
if content.startswith('---'):
parts = content.split('---', 2)
if len(parts) >= 3:
metadata = yaml.safe_load(parts[1])
content = parts[2]
# Determine doc type from path
doc_type = self._infer_doc_type(file_path)
# Chunk by headers
chunks = self._chunk_by_headers(content)
documents = []
for i, chunk in enumerate(chunks):
documents.append(Document(
content=chunk['content'],
metadata={
**metadata,
'section': chunk['header'],
'chunk_index': i,
'file_path': str(file_path),
},
source=str(file_path.relative_to(self.docs_path)),
doc_type=doc_type,
))
return documents
def _chunk_by_headers(self, content: str) -> List[Dict[str, str]]:
"""Split content into chunks based on markdown headers"""
# Match headers at different levels
header_pattern = r'^(#{1,3})\s+(.+)$'
lines = content.split('\n')
chunks = []
current_chunk = {'header': 'Introduction', 'content': ''}
for line in lines:
header_match = re.match(header_pattern, line)
if header_match:
# Save current chunk if it has content
if current_chunk['content'].strip():
chunks.append(current_chunk)
# Start new chunk
current_chunk = {
'header': header_match.group(2),
'content': line + '\n'
}
else:
current_chunk['content'] += line + '\n'
# Add final chunk
if current_chunk['content'].strip():
chunks.append(current_chunk)
return chunks
def _load_openapi(self, file_path: Path) -> List[Document]:
"""Load OpenAPI spec and create documents for each endpoint"""
with open(file_path, 'r') as f:
spec = yaml.safe_load(f)
documents = []
for path, methods in spec.get('paths', {}).items():
for method, details in methods.items():
if method in ['get', 'post', 'put', 'delete', 'patch']:
content = self._format_endpoint_doc(path, method, details)
documents.append(Document(
content=content,
metadata={
'endpoint': path,
'method': method.upper(),
'tags': details.get('tags', []),
'operation_id': details.get('operationId'),
},
source=str(file_path.relative_to(self.docs_path)),
doc_type='api',
))
return documents
def _format_endpoint_doc(self, path: str, method: str, details: Dict) -> str:
"""Format API endpoint as readable documentation"""
doc = f"# {method.upper()} {path}\n\n"
doc += f"{details.get('summary', '')}\n\n"
doc += f"{details.get('description', '')}\n\n"
# Parameters
if params := details.get('parameters'):
doc += "## Parameters\n\n"
for param in params:
required = '(required)' if param.get('required') else '(optional)'
doc += f"- **{param['name']}** {required}: {param.get('description', '')}\n"
# Request body
if request_body := details.get('requestBody'):
doc += "\n## Request Body\n\n"
doc += f"{request_body.get('description', '')}\n"
# Responses
if responses := details.get('responses'):
doc += "\n## Responses\n\n"
for status, response in responses.items():
doc += f"- **{status}**: {response.get('description', '')}\n"
return doc
def _load_code_example(self, file_path: Path) -> List[Document]:
"""Load code examples as documentation"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# Extract docstring as description
description = ""
if '"""' in content:
match = re.search(r'"""(.+?)"""', content, re.DOTALL)
if match:
description = match.group(1).strip()
return [Document(
content=f"# Code Example: {file_path.stem}\n\n{description}\n\n```python\n{content}\n```",
metadata={
'file_name': file_path.name,
'language': 'python',
},
source=str(file_path.relative_to(self.docs_path)),
doc_type='example',
)]
def _infer_doc_type(self, file_path: Path) -> str:
"""Infer document type from file path"""
path_str = str(file_path).lower()
if 'api' in path_str:
return 'api'
elif 'guide' in path_str or 'tutorial' in path_str:
return 'guide'
elif 'readme' in path_str:
return 'readme'
return 'general'Step 2: Index Documentation with Embeddings
Create embeddings and store them in a vector database for fast retrieval:
# src/indexing/vector_store.py
from typing import List, Optional
import numpy as np
from sentence_transformers import SentenceTransformer
import chromadb
from chromadb.config import Settings
class DocumentIndexer:
"""Index documents in a vector database"""
def __init__(
self,
embedding_model: str = "BAAI/bge-large-en-v1.5",
collection_name: str = "documentation",
persist_directory: str = "./chroma_db"
):
# Load embedding model
self.embedder = SentenceTransformer(embedding_model)
# Initialize ChromaDB
self.chroma_client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(anonymized_telemetry=False)
)
# Get or create collection
self.collection = self.chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"} # Use cosine similarity
)
def index_documents(self, documents: List[Document], batch_size: int = 100):
"""Index documents in batches"""
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
# Generate embeddings
texts = [doc.content for doc in batch]
embeddings = self.embedder.encode(texts, show_progress_bar=True)
# Prepare data for ChromaDB
ids = [f"{doc.source}_{doc.metadata.get('chunk_index', i)}"
for i, doc in enumerate(batch)]
metadatas = [
{
"source": doc.source,
"doc_type": doc.doc_type,
**{k: str(v) for k, v in doc.metadata.items()}
}
for doc in batch
]
# Add to collection
self.collection.add(
ids=ids,
embeddings=embeddings.tolist(),
documents=texts,
metadatas=metadatas
)
print(f"Indexed {len(documents)} documents")
def search(
self,
query: str,
n_results: int = 5,
doc_type_filter: Optional[str] = None
) -> List[dict]:
"""Search for relevant documents"""
# Generate query embedding
query_embedding = self.embedder.encode([query])[0]
# Build filter
where_filter = None
if doc_type_filter:
where_filter = {"doc_type": doc_type_filter}
# Query collection
results = self.collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=n_results,
where=where_filter,
include=["documents", "metadatas", "distances"]
)
# Format results
formatted_results = []
for i in range(len(results['ids'][0])):
formatted_results.append({
'id': results['ids'][0][i],
'content': results['documents'][0][i],
'metadata': results['metadatas'][0][i],
'score': 1 - results['distances'][0][i], # Convert distance to similarity
})
return formatted_results
# Alternative: Using Qdrant for production
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
class QdrantIndexer:
"""Production-ready indexer using Qdrant"""
def __init__(
self,
embedding_model: str = "BAAI/bge-large-en-v1.5",
collection_name: str = "documentation",
qdrant_url: str = "http://localhost:6333"
):
self.embedder = SentenceTransformer(embedding_model)
self.embedding_dim = self.embedder.get_sentence_embedding_dimension()
self.client = QdrantClient(url=qdrant_url)
self.collection_name = collection_name
# Create collection if not exists
collections = [c.name for c in self.client.get_collections().collections]
if collection_name not in collections:
self.client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(
size=self.embedding_dim,
distance=Distance.COSINE
)
)
def index_documents(self, documents: List[Document], batch_size: int = 100):
"""Index documents with Qdrant"""
points = []
for i, doc in enumerate(documents):
embedding = self.embedder.encode(doc.content)
points.append(PointStruct(
id=i,
vector=embedding.tolist(),
payload={
"content": doc.content,
"source": doc.source,
"doc_type": doc.doc_type,
**doc.metadata
}
))
# Upsert in batches
for i in range(0, len(points), batch_size):
batch = points[i:i + batch_size]
self.client.upsert(
collection_name=self.collection_name,
points=batch
)Step 3: Connect an Open-Source LLM
Set up the LLM for generating responses based on retrieved documentation:
# src/llm/model_server.py
from typing import List, Optional, Generator
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
class DocumentationLLM:
"""LLM wrapper for documentation Q&A"""
def __init__(
self,
model_name: str = "mistralai/Mistral-7B-Instruct-v0.3",
device: str = "cuda",
max_new_tokens: int = 1024,
):
self.device = device
self.max_new_tokens = max_new_tokens
# Load model and tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
)
# Set padding token
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def generate_response(
self,
query: str,
context_docs: List[dict],
conversation_history: Optional[List[dict]] = None,
) -> str:
"""Generate a response based on retrieved documents"""
# Build context from retrieved documents
context = self._format_context(context_docs)
# Build prompt
prompt = self._build_prompt(query, context, conversation_history)
# Tokenize
inputs = self.tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=4096
).to(self.device)
# Generate
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=self.max_new_tokens,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=self.tokenizer.pad_token_id,
)
# Decode response
response = self.tokenizer.decode(
outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True
)
return response.strip()
def generate_stream(
self,
query: str,
context_docs: List[dict],
conversation_history: Optional[List[dict]] = None,
) -> Generator[str, None, None]:
"""Generate response with streaming"""
context = self._format_context(context_docs)
prompt = self._build_prompt(query, context, conversation_history)
inputs = self.tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=4096
).to(self.device)
# Set up streamer
streamer = TextIteratorStreamer(
self.tokenizer,
skip_special_tokens=True,
skip_prompt=True
)
# Generate in separate thread
generation_kwargs = {
**inputs,
"max_new_tokens": self.max_new_tokens,
"temperature": 0.7,
"top_p": 0.9,
"do_sample": True,
"streamer": streamer,
}
thread = Thread(target=self.model.generate, kwargs=generation_kwargs)
thread.start()
# Yield tokens as they're generated
for token in streamer:
yield token
def _format_context(self, docs: List[dict]) -> str:
"""Format retrieved documents as context"""
context_parts = []
for i, doc in enumerate(docs, 1):
source = doc.get('metadata', {}).get('source', 'Unknown')
context_parts.append(
f"[Document {i}]\nSource: {source}\n{doc['content']}\n"
)
return "\n---\n".join(context_parts)
def _build_prompt(self, query: str, context: str, history: Optional[List[dict]]) -> str:
"""Build the full prompt with system instructions"""
system_prompt = """You are a helpful documentation assistant. Your role is to answer
questions about the codebase and APIs based on the provided documentation context.
Guidelines:
- Answer based ONLY on the provided documentation context
- If the answer is not in the context, say "I don't have information about that in the documentation"
- Include code examples when relevant
- Reference the source document when appropriate
- Be concise but comprehensive
- Format code blocks with appropriate language tags"""
# Mistral-style prompt format
prompt = f"[INST] {system_prompt}\n\n"
prompt += f"Documentation Context:\n{context}\n\n"
# Add conversation history
if history:
for msg in history[-4:]: # Keep last 4 exchanges
if msg['role'] == 'user':
prompt += f"User: {msg['content']}\n"
else:
prompt += f"Assistant: {msg['content']}\n"
prompt += f"User Question: {query} [/INST]"
return prompt
# Using Ollama for simpler deployment
import ollama
class OllamaLLM:
"""Use Ollama for easy local LLM deployment"""
def __init__(self, model: str = "llama3:8b"):
self.model = model
def generate_response(
self,
query: str,
context_docs: List[dict],
conversation_history: Optional[List[dict]] = None,
) -> str:
context = "\n---\n".join([doc['content'] for doc in context_docs])
messages = [
{
"role": "system",
"content": "You are a documentation assistant. Answer questions based only on the provided context. Include code examples when helpful."
},
{
"role": "user",
"content": f"Context:\n{context}\n\nQuestion: {query}"
}
]
response = ollama.chat(model=self.model, messages=messages)
return response['message']['content']Step 4: Build the Complete Chatbot
Combine all components into a complete RAG chatbot:
# src/chatbot/documentation_chatbot.py
from typing import List, Optional, Generator
from dataclasses import dataclass
import logging
logger = logging.getLogger(__name__)
@dataclass
class ChatMessage:
role: str # 'user' or 'assistant'
content: str
sources: Optional[List[str]] = None
class DocumentationChatbot:
"""Complete RAG chatbot for documentation"""
def __init__(
self,
indexer: DocumentIndexer,
llm: DocumentationLLM,
reranker: Optional["Reranker"] = None,
retrieval_k: int = 5,
rerank_k: int = 3,
):
self.indexer = indexer
self.llm = llm
self.reranker = reranker
self.retrieval_k = retrieval_k
self.rerank_k = rerank_k
self.conversation_history: List[ChatMessage] = []
def chat(self, query: str) -> ChatMessage:
"""Process a user query and return a response"""
# Step 1: Retrieve relevant documents
retrieved_docs = self.indexer.search(
query=query,
n_results=self.retrieval_k
)
logger.info(f"Retrieved {len(retrieved_docs)} documents")
# Step 2: Rerank if reranker is available
if self.reranker and len(retrieved_docs) > self.rerank_k:
retrieved_docs = self.reranker.rerank(
query=query,
documents=retrieved_docs,
top_k=self.rerank_k
)
# Step 3: Generate response
history = [
{"role": msg.role, "content": msg.content}
for msg in self.conversation_history[-4:]
]
response_text = self.llm.generate_response(
query=query,
context_docs=retrieved_docs,
conversation_history=history
)
# Step 4: Extract sources
sources = [
doc.get('metadata', {}).get('source', 'Unknown')
for doc in retrieved_docs
]
# Step 5: Update conversation history
self.conversation_history.append(ChatMessage(
role='user',
content=query
))
response_message = ChatMessage(
role='assistant',
content=response_text,
sources=list(set(sources)) # Deduplicate
)
self.conversation_history.append(response_message)
return response_message
def chat_stream(self, query: str) -> Generator[str, None, None]:
"""Stream response for real-time display"""
retrieved_docs = self.indexer.search(
query=query,
n_results=self.retrieval_k
)
if self.reranker and len(retrieved_docs) > self.rerank_k:
retrieved_docs = self.reranker.rerank(
query=query,
documents=retrieved_docs,
top_k=self.rerank_k
)
history = [
{"role": msg.role, "content": msg.content}
for msg in self.conversation_history[-4:]
]
full_response = ""
for token in self.llm.generate_stream(
query=query,
context_docs=retrieved_docs,
conversation_history=history
):
full_response += token
yield token
# Update history after streaming completes
self.conversation_history.append(ChatMessage(role='user', content=query))
self.conversation_history.append(ChatMessage(
role='assistant',
content=full_response,
sources=[doc.get('metadata', {}).get('source') for doc in retrieved_docs]
))
def clear_history(self):
"""Clear conversation history"""
self.conversation_history = []Step 5: API and UI
# src/api/main.py
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
from typing import List, Optional
import json
app = FastAPI(title="Documentation Chatbot API")
# Initialize chatbot (in production, use dependency injection)
chatbot = None
def get_chatbot():
global chatbot
if chatbot is None:
loader = DocumentationLoader("./docs")
docs = loader.load_all()
indexer = DocumentIndexer()
indexer.index_documents(docs)
llm = OllamaLLM(model="llama3:8b")
chatbot = DocumentationChatbot(indexer=indexer, llm=llm)
return chatbot
class ChatRequest(BaseModel):
query: str
stream: bool = False
class ChatResponse(BaseModel):
response: str
sources: List[str]
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
"""Chat endpoint for documentation queries"""
bot = get_chatbot()
if request.stream:
async def generate():
for token in bot.chat_stream(request.query):
yield f"data: {json.dumps({'token': token})}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(
generate(),
media_type="text/event-stream"
)
response = bot.chat(request.query)
return ChatResponse(
response=response.content,
sources=response.sources or []
)
@app.post("/clear")
async def clear_history():
"""Clear conversation history"""
get_chatbot().clear_history()
return {"status": "cleared"}
@app.get("/health")
async def health():
return {"status": "healthy"}Common Mistakes to Avoid
Poor chunking strategy: Splitting documents at arbitrary character limits breaks context. Always chunk at logical boundaries (headers, paragraphs, code blocks).
Ignoring metadata: Source attribution and document types enable better filtering and user trust. Always preserve and expose this information.
Not handling out-of-scope queries: Your prompt must instruct the LLM to acknowledge when it doesn’t have relevant information rather than hallucinating answers.
Skipping reranking: Initial retrieval often returns marginally relevant documents. A reranker significantly improves response quality for the cost of slight latency.
Stale embeddings: Documentation changes frequently. Set up automated re-indexing when docs are updated.
Ignoring evaluation: Track metrics like answer relevance, retrieval accuracy, and user feedback to continuously improve your chatbot.
Conclusion
Building a chatbot for developer documentation with open-source LLMs can transform how teams interact with their knowledge base. It saves time, reduces frustration, and makes onboarding smoother—studies show developers can find answers 3-5x faster with a well-implemented documentation chatbot.
The best approach combines an open-source LLM with a well-structured RAG pipeline: smart chunking, quality embeddings, optional reranking, and clear prompting. This ensures your chatbot becomes a reliable assistant that developers actually want to use.
Start with a simple setup using Ollama and ChromaDB, then scale to production-grade solutions like vLLM and Qdrant as your needs grow. The key is iterating based on real user queries and continuously improving retrieval quality.
If you’re interested in applying AI to your workflow, see our post on Automating Documentation with AI. For hands-on tutorials, check out LangChain’s documentation.