Unit tests are essential for ensuring code quality and catching bugs early. However, writing them manually consumes significant development time, and testing often falls to the bottom of priority lists when deadlines loom.
With large language models (LLMs) like ChatGPT, Claude, and GitHub Copilot, generating unit tests automatically is now a reality. These tools can draft test cases in seconds, providing teams with a starting point to improve coverage without the tedious boilerplate work.
In this article, you’ll learn the benefits and risks of using LLMs for unit test generation, see practical examples of effective prompts, and discover how to integrate AI-assisted testing into your workflow without compromising test quality.
How LLMs Generate Unit Tests
Before examining benefits and risks, understanding how LLMs approach test generation helps set realistic expectations. LLMs analyze code patterns, function signatures, and contextual clues to produce test cases.
Pattern Recognition
LLMs have been trained on millions of test files across different frameworks and languages. When you provide a function, the model recognizes patterns similar to code it has seen before and generates tests matching those patterns.
For example, given this Python function:
def calculate_discount(price: float, discount_percent: float) -> float:
"""Calculate discounted price. Raises ValueError for invalid inputs."""
if price < 0 or discount_percent < 0 or discount_percent > 100:
raise ValueError("Invalid price or discount percentage")
return price * (1 - discount_percent / 100)
An LLM might generate:
import pytest
from pricing import calculate_discount
class TestCalculateDiscount:
def test_zero_discount(self):
assert calculate_discount(100.0, 0) == 100.0
def test_full_discount(self):
assert calculate_discount(100.0, 100) == 0.0
def test_partial_discount(self):
assert calculate_discount(200.0, 25) == 150.0
def test_negative_price_raises_error(self):
with pytest.raises(ValueError):
calculate_discount(-50.0, 10)
def test_negative_discount_raises_error(self):
with pytest.raises(ValueError):
calculate_discount(100.0, -10)
def test_discount_over_100_raises_error(self):
with pytest.raises(ValueError):
calculate_discount(100.0, 150)
The LLM recognized the validation logic and generated appropriate edge case tests. This pattern recognition works across languages and frameworks.
Context Window Limitations
LLMs have limited context windows, meaning they can only consider a certain amount of code at once. For isolated functions, this works well. For complex systems with intricate dependencies, the model may miss crucial interactions that affect test validity.
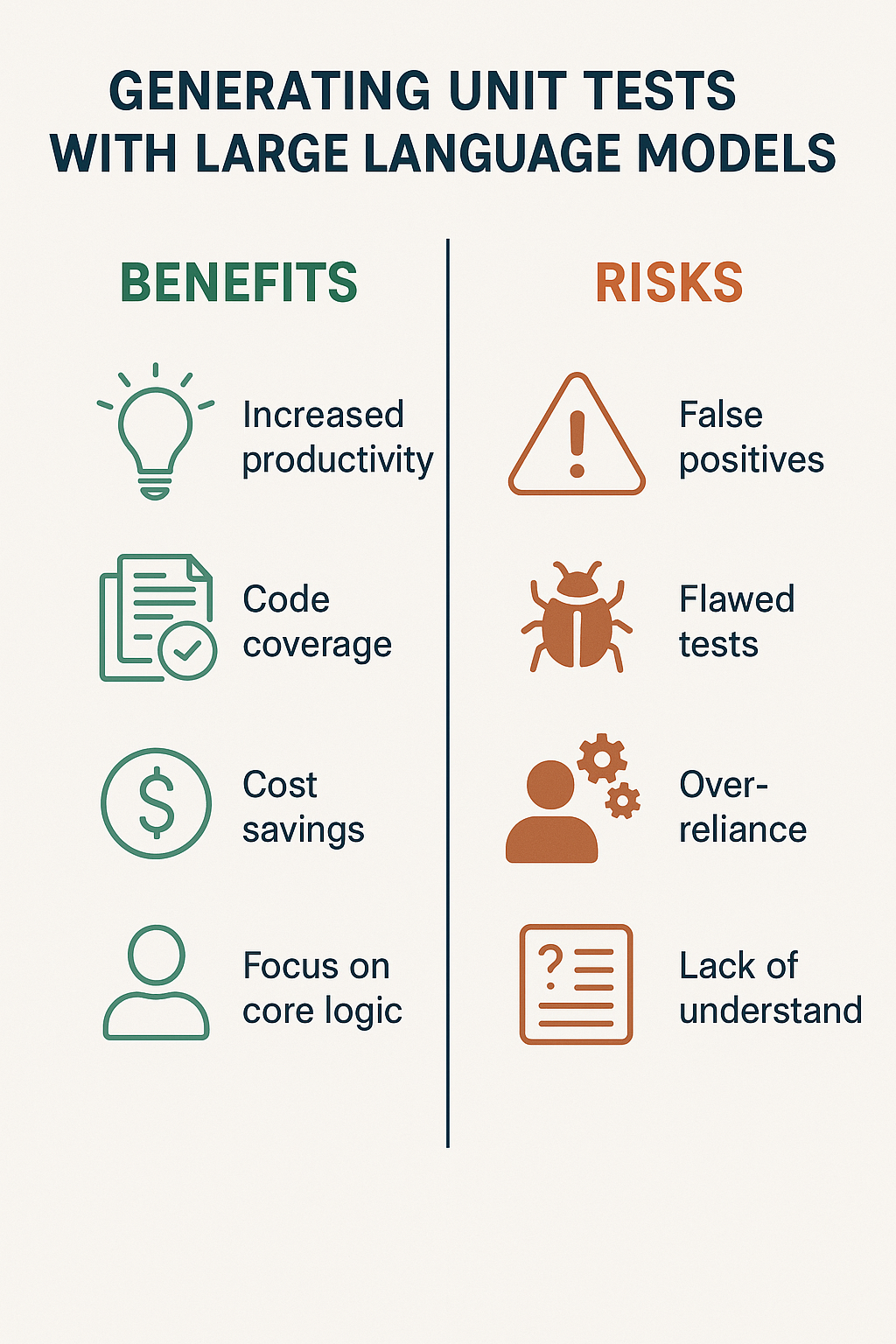
Benefits of AI-Generated Unit Tests
When used appropriately, LLM-generated tests offer substantial productivity gains. Several key benefits emerge from practical usage.
Accelerated Test Creation
Instead of spending hours writing boilerplate tests, developers can generate dozens of test cases in minutes. The time saved on mechanical work allows more focus on business logic validation and complex integration scenarios.
Consider a typical data access object with CRUD operations. Manually writing tests for create, read, update, delete, and error conditions might take 30-45 minutes. An LLM can generate a comprehensive starting point in under a minute.
// Example prompt for comprehensive DAO tests
// "Generate Jest tests for this UserRepository class that covers:
// - All CRUD operations
// - Database connection errors
// - Validation failures
// - Concurrent access scenarios"
import { UserRepository } from './userRepository';
import { DatabaseConnection } from './database';
jest.mock('./database');
describe('UserRepository', () => {
let repository: UserRepository;
let mockDb: jest.Mocked<DatabaseConnection>;
beforeEach(() => {
mockDb = new DatabaseConnection() as jest.Mocked<DatabaseConnection>;
repository = new UserRepository(mockDb);
});
describe('create', () => {
it('should insert user and return generated id', async () => {
mockDb.execute.mockResolvedValue({ insertId: 42 });
const result = await repository.create({
name: 'John Doe',
email: 'john@example.com'
});
expect(result.id).toBe(42);
expect(mockDb.execute).toHaveBeenCalledWith(
expect.stringContaining('INSERT INTO users'),
expect.arrayContaining(['John Doe', 'john@example.com'])
);
});
it('should throw ValidationError for invalid email', async () => {
await expect(
repository.create({ name: 'John', email: 'invalid-email' })
).rejects.toThrow('ValidationError');
});
it('should handle database connection failures', async () => {
mockDb.execute.mockRejectedValue(new Error('Connection refused'));
await expect(
repository.create({ name: 'John', email: 'john@example.com' })
).rejects.toThrow('Database unavailable');
});
});
// ... additional test suites for read, update, delete
});
Improved Coverage Through Edge Case Detection
LLMs can suggest edge cases that developers might overlook due to familiarity blindness. When you’ve written a function, you tend to think about how it should work. LLMs approach the code fresh and may identify boundary conditions you hadn’t considered.
Common edge cases LLMs catch include:
- Empty arrays or null inputs
- Boundary values (0, -1, MAX_INT)
- Unicode and special characters in strings
- Timezone edge cases in date handling
- Race conditions in async operations
Lower Barrier for Junior Developers
For teams with junior developers learning testing practices, AI-generated tests provide ready-made examples of proper test structure. Juniors can study the generated tests to understand patterns like arrange-act-assert, proper mocking, and assertion specificity.
Rather than struggling with testing syntax, new developers can focus on understanding what makes tests valuable and how to verify business requirements.
Consistent Test Formatting
AI tools can help enforce a consistent format for tests across the entire codebase. By using system prompts or configuration, you can ensure all generated tests follow your team’s naming conventions, assertion styles, and organizational patterns.
// System prompt for consistent test generation:
// "Follow these conventions:
// - Use describe/it blocks for organization
// - Name tests using 'should [expected behavior] when [condition]'
// - Use AAA pattern (Arrange, Act, Assert) with blank lines between sections
// - Prefer specific assertions over generic equality checks"
Risks of Relying on LLMs for Tests
Despite the benefits, LLM-generated tests carry significant risks that require mitigation. Understanding these risks helps you use AI assistance responsibly.
Shallow Understanding of Business Logic
LLMs don’t understand your business domain. They generate tests based on code patterns, not business requirements. A function that calculates loan interest might receive mathematically correct tests that completely miss regulatory compliance requirements.
Consider this example:
def calculate_loan_payment(principal, annual_rate, months):
monthly_rate = annual_rate / 12 / 100
payment = principal * (monthly_rate * (1 + monthly_rate)**months) /
((1 + monthly_rate)**months - 1)
return round(payment, 2)
An LLM might generate tests verifying the math is correct. However, it won’t know that:
- Your company caps rates at 36% APR due to usury laws
- Certain states require different rounding rules
- Minimum payment amounts apply to specific loan types
These business rules require human knowledge to test properly.
False Sense of Security
High test coverage numbers can create dangerous overconfidence. Developers might assume 90% coverage means the code is well-tested. However, coverage without meaningful assertions is misleading.
LLMs sometimes generate tests that execute code paths without verifying meaningful outcomes:
// Problematic AI-generated test - executes code but verifies nothing meaningful
it('should process order', () => {
const order = createOrder();
const result = orderService.process(order);
expect(result).toBeDefined(); // This assertion is nearly useless
});
// Better test - verifies actual business outcomes
it('should calculate total including tax and shipping', () => {
const order = createOrder({
items: [{ price: 100, quantity: 2 }],
shippingMethod: 'express',
taxRate: 0.08
});
const result = orderService.process(order);
expect(result.subtotal).toBe(200);
expect(result.tax).toBe(16);
expect(result.shipping).toBe(15);
expect(result.total).toBe(231);
});
Fragile Test Generation
Generated tests may break when the code evolves. LLMs often create tests tightly coupled to implementation details rather than behavior, leading to high maintenance burden.
For instance, tests that verify exact mock call counts or specific internal method invocations break whenever refactoring occurs—even if the external behavior remains unchanged.
// Fragile: coupled to implementation
it('should call database exactly twice', () => {
userService.getActiveUsers();
expect(mockDb.query).toHaveBeenCalledTimes(2);
});
// Robust: tests behavior, not implementation
it('should return only active users', () => {
mockDb.query.mockResolvedValue([
{ id: 1, name: 'Active', status: 'active' },
{ id: 2, name: 'Inactive', status: 'inactive' }
]);
const result = await userService.getActiveUsers();
expect(result).toHaveLength(1);
expect(result[0].name).toBe('Active');
});
Security and Privacy Concerns
Sharing proprietary code with third-party AI tools may create compliance or security concerns. Before using external LLM services for test generation, consider:
- Does your code contain sensitive business logic?
- Are there regulatory requirements around code handling (HIPAA, PCI-DSS)?
- Does your employment agreement restrict sharing code with third parties?
- What data retention policies does the AI provider have?
Self-hosted models or enterprise agreements with strict data policies can mitigate these concerns for sensitive codebases.
Hallucinated Assertions
LLMs occasionally generate tests with incorrect expected values. They may “hallucinate” what they think the output should be rather than computing it correctly.
// AI might generate this incorrect assertion
it('should calculate compound interest', () => {
const result = calculateCompoundInterest(1000, 0.05, 12);
expect(result).toBe(1051.16); // Wrong! Actual is 1051.16 for simple, not compound
});
Always verify expected values in generated tests before committing them.
Best Practices for LLM Test Generation
Maximizing benefits while minimizing risks requires intentional practices. These guidelines help teams use AI-assisted testing effectively.
Treat Generated Tests as First Drafts
Never commit AI-generated tests without review. Use them as a starting point that saves time on boilerplate, then refine assertions to align with actual business requirements.
A practical workflow:
- Generate initial test structure with LLM
- Review each test for correctness and relevance
- Add missing business logic tests
- Remove or rewrite weak assertions
- Run tests and verify they pass for the right reasons
Provide Rich Context in Prompts
Better prompts produce better tests. Include relevant context about business rules, expected behaviors, and edge cases you want covered.
// Poor prompt:
// "Write tests for this function"
// Better prompt:
// "Write comprehensive Jest tests for this payment validation function.
// Business context:
// - Payments under $10 are rejected
// - International payments require additional verification
// - CVV is required for first-time cards only
// - Rate limiting applies: max 3 attempts per minute
// Include tests for happy paths, validation failures, and rate limiting."
Combine with Coverage Tools
Use coverage tools alongside AI generation to identify gaps. After generating tests, run coverage analysis to find untested branches and paths. Then prompt the LLM specifically for those scenarios.
# Run coverage to find gaps
npm test -- --coverage
# Identify uncovered lines, then prompt:
# "Generate tests covering lines 45-52 of paymentProcessor.ts,
# specifically the retry logic when payment gateway times out"
Integrate into CI/CD with Human Gates
If using automated test generation in pipelines, require human approval before merging. Automated generation can create pull requests with suggested tests, but a developer should review and approve.
# Example GitHub Actions workflow
name: Generate Test Suggestions
on:
pull_request:
types: [opened]
jobs:
suggest-tests:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Analyze changed files
run: |
# Identify changed source files
# Generate test suggestions via AI
# Create review comment with suggestions
- name: Post review comment
# Suggestions posted as PR comment, not auto-committed
Establish Test Quality Criteria
Define what makes a good test in your codebase and verify generated tests meet those criteria:
- Isolation: Tests don’t depend on external state or other tests
- Determinism: Tests produce the same result every run
- Specificity: Assertions verify specific outcomes, not just “something happened”
- Readability: Test names clearly describe the scenario being tested
- Maintainability: Tests target behavior, not implementation details
Effective Prompts for Test Generation
The quality of generated tests depends heavily on prompt quality. Here are prompt patterns that produce useful results:
Behavior-Focused Prompts
// Prompt structure:
// "Generate [framework] tests for [function/class] that verify:
// 1. [Expected behavior in scenario A]
// 2. [Expected behavior in scenario B]
// 3. [Error handling for condition C]
// Use [specific patterns/conventions]."
// Example:
// "Generate pytest tests for the UserAuthentication class that verify:
// 1. Successful login returns a valid JWT token
// 2. Failed login after 3 attempts locks the account for 15 minutes
// 3. Expired tokens are rejected with 401 status
// 4. Token refresh extends session without re-authentication
// Use pytest fixtures for database setup and mock external services."
Edge Case Exploration Prompts
// "Analyze this function and generate tests for edge cases including:
// - Boundary values
// - Null/undefined inputs
// - Empty collections
// - Type coercion issues
// - Concurrency scenarios
// For each edge case, explain why it matters."
Mutation Testing Prompts
// "Review these existing tests and identify mutations that would
// survive (not be caught). Then generate additional tests to catch:
// - Off-by-one errors
// - Comparison operator swaps (< vs <=)
// - Boolean logic inversions
// - Missing null checks"
When NOT to Use LLM-Generated Tests
Some scenarios warrant fully manual test writing:
- Security-critical code: Authentication, encryption, and access control deserve meticulous human attention
- Financial calculations: Rounding, currency conversion, and tax calculations need verified assertions
- Compliance requirements: Regulatory tests often require documentation trails that AI can't provide
- Complex integration scenarios: Multi-system interactions need human understanding of system boundaries
Conclusion
Generating unit tests with large language models can accelerate development, improve coverage, and reduce repetitive work. However, AI-generated tests are not a replacement for thoughtful test design.
The most effective approach combines AI efficiency with human judgment: let LLMs draft the scaffolding while developers refine assertions, add business logic validation, and ensure alignment with requirements. Treat generated tests as first drafts, not finished products.
If you're interested in testing strategies for specific frameworks, check out our guide on Unit, Widget, and Integration Testing in Flutter: Best Practices. For understanding how AI tools integrate into development workflows, explore our post on AI-Powered Code Review Best Practices.


1 Comment