Large language models are powerful, but they do not know your data. Retrieval-augmented generation (RAG) solves that gap by combining information retrieval with generation. Instead of asking a model to “remember” everything, you retrieve the right context at runtime and let the model reason over it.
This guide explains RAG from scratch for developers building production AI features. You will learn how RAG works end-to-end, why it outperforms prompt-only approaches, and how to design a reliable pipeline without overengineering.
Why Prompt-Only LLMs Break Down
Prompting an LLM with long instructions and pasted documents works for demos. However, it fails at scale. Context windows are limited, updates require re-prompting, and answers drift as prompts grow.
More importantly, prompt-only systems lack grounding. The model guesses when information is missing. RAG changes that by making retrieval explicit and verifiable.
If you have already explored using LLMs for refactoring or reviews, as discussed in using AI for code refactoring, you have likely seen these limitations first-hand.
What RAG Actually Is
RAG is not a model. It is a pattern.
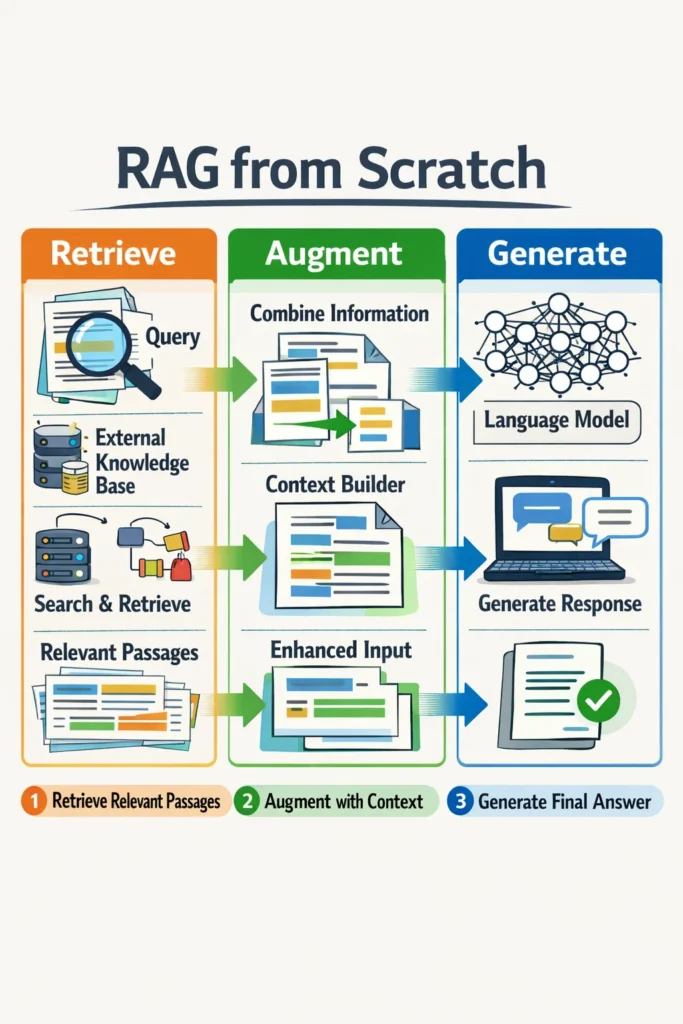
At a high level, a RAG system does three things:
- Stores your knowledge in a retrievable form
- Retrieves the most relevant pieces for a query
- Feeds that context to an LLM to generate an answer
The model does not memorize your data. It reasons over retrieved context at request time. This separation is the key to reliability.
The Core RAG Pipeline
Every RAG implementation, regardless of tooling, follows the same pipeline.
Step 1: Ingest and Chunk Data
Source data can include documentation, database records, PDFs, or code. This data is split into chunks that are small enough to retrieve efficiently but large enough to preserve meaning.
Chunking strategy matters. Overly small chunks lose context, while large chunks reduce retrieval precision. In practice, teams iterate on chunk size based on query patterns.
Step 2: Create Embeddings
Each chunk is converted into a vector representation using an embedding model. These vectors capture semantic meaning rather than keywords.
Embeddings enable similarity search, which is why RAG systems can retrieve relevant content even when queries are phrased differently from the source text.
Step 3: Store Vectors in a Vector Database
Vectors are stored in a system optimized for similarity search. This can be a dedicated vector database or a hybrid solution layered on top of an existing datastore.
At this stage, metadata becomes critical. Storing source identifiers, timestamps, and permissions alongside vectors enables filtering and access control later.
Step 4: Retrieve Relevant Context
When a user asks a question, the query is embedded and compared against stored vectors. The top-k most relevant chunks are selected.
This retrieval step is the backbone of RAG. Poor retrieval leads to poor answers, regardless of how strong the model is.
Step 5: Generate the Answer
The retrieved chunks are injected into the prompt as context. The LLM then generates an answer grounded in those sources.
Because the context is explicit, answers become more accurate, auditable, and updatable.
Why RAG Improves Accuracy and Trust
RAG systems reduce hallucinations by constraining the model’s reasoning space. The model no longer invents facts when it lacks knowledge. Instead, it relies on retrieved content.
This approach also improves maintainability. Updating knowledge means re-indexing data, not retraining or re-prompting models.
In production systems, this distinction is crucial. It mirrors the same architectural separation you see in API design, where data access and business logic are decoupled. If that parallel resonates, REST vs GraphQL vs gRPC offers a useful comparison mindset.
A Realistic RAG Use Case
Consider an internal developer assistant that answers questions about company architecture. Documentation lives across repositories and wikis, and it changes frequently.
A prompt-only approach requires constantly updating instructions and still produces outdated answers. With RAG, documentation is indexed, retrieved on demand, and injected into the model’s context.
As documentation evolves, re-indexing keeps answers current. The assistant becomes a reliable interface to living knowledge rather than a static snapshot.
Common RAG Mistakes
One common mistake is treating RAG as “LLM plus database.” Retrieval quality is often ignored. Without good chunking, embeddings, and filters, RAG performs poorly.
Another issue is retrieving too much context. Overloading the prompt dilutes relevance and increases cost. Fewer, higher-quality chunks usually outperform brute-force context stuffing.
Finally, many teams skip evaluation. RAG systems must be tested with real queries to validate retrieval quality, not just generation fluency.
When to Use RAG
- Your data changes frequently
- Answers must be grounded in specific sources
- You need transparency and traceability
- Prompt-only solutions are becoming brittle
When NOT to Use RAG
- The task is purely creative
- The knowledge base is tiny and static
- Latency requirements cannot tolerate retrieval
- Simplicity matters more than accuracy
RAG and System Architecture
RAG fits naturally into modern backend architectures. Retrieval can be treated as a service, generation as another. This separation allows independent scaling, caching, and monitoring.
If you are already thinking in terms of service boundaries and observability, concepts from monitoring and logging in microservices apply directly to RAG pipelines as well.
Conclusion
RAG from scratch is about discipline, not novelty. By separating retrieval from generation, you gain accuracy, control, and maintainability. The model becomes a reasoning engine, not a knowledge vault.
A practical next step is to build a minimal RAG pipeline with a small dataset, evaluate retrieval quality, and iterate on chunking and filters. That foundation scales far better than increasingly complex prompts and sets you up for reliable AI systems in production.


1 Comment