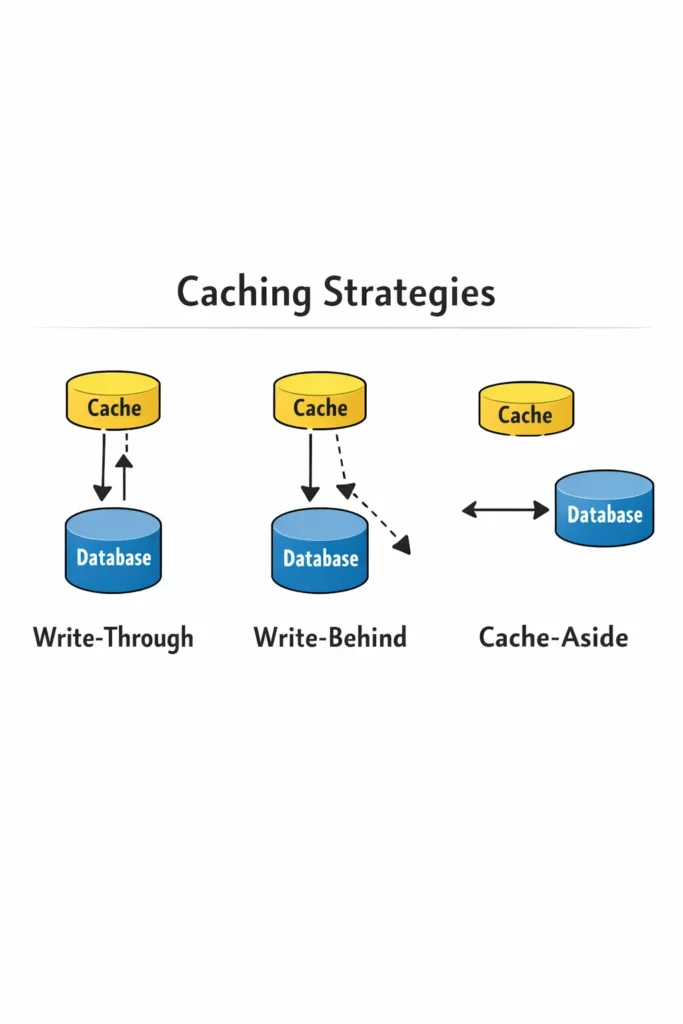
Caching is one of the most effective ways to improve application performance, but choosing the wrong caching strategy can introduce stale data bugs, consistency problems, and operational headaches that are harder to debug than the performance problem you were trying to solve. The difference between a cache that makes your application faster and one that makes it unreliable comes down to understanding how data flows between your application, cache, and database.
This deep dive covers the four primary caching strategies — cache-aside, read-through, write-through, and write-behind — with production implementations, consistency trade-offs, and clear guidance on which strategy fits which use case. By the end, you will know which caching strategies to reach for and, equally important, which ones to avoid for your specific data patterns.
Why Caching Strategies Matter
Adding a cache without choosing a deliberate strategy is like adding an index without understanding query patterns — it might help, it might not, and it might make things worse in ways you do not expect. Each caching strategy answers two fundamental questions differently:
- Who is responsible for populating the cache? The application code, the cache library, or an automated process?
- When does the cache update after a write? Immediately, asynchronously, or never (invalidate and repopulate on next read)?
The answers to these questions determine your consistency guarantees, write latency, read latency, and failure modes. Consequently, the “best” caching strategy depends entirely on your application’s tolerance for stale data and its read-to-write ratio.
Cache-Aside (Lazy Loading)
Cache-aside is the most common caching strategy and the one most developers implement first. The application manages the cache explicitly — it checks the cache before querying the database, and it populates the cache after a database read.
How Cache-Aside Works
Read path:
- Application checks the cache for the requested data
- If found (cache hit), return the cached value
- If not found (cache miss), query the database
- Store the database result in the cache with a TTL
- Return the result to the caller
Write path:
- Application writes to the database
- Application invalidates (deletes) the corresponding cache entry
- The next read triggers a cache miss and repopulates the cache from the database
import redis
import json
from typing import Optional
cache = redis.Redis(host='cache.internal', port=6379, decode_responses=True)
CACHE_TTL = 3600 # 1 hour
def get_product(product_id: int) -> Optional[dict]:
# Step 1: Check cache
cache_key = f"product:{product_id}"
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
# Step 2: Cache miss — query database
product = db.execute(
"SELECT * FROM products WHERE id = %s", (product_id,)
).fetchone()
if product is None:
return None
# Step 3: Populate cache for future reads
product_dict = dict(product)
cache.setex(cache_key, CACHE_TTL, json.dumps(product_dict))
return product_dict
def update_product(product_id: int, updates: dict):
# Step 1: Update database
db.execute(
"UPDATE products SET name = %s, price = %s WHERE id = %s",
(updates["name"], updates["price"], product_id)
)
db.commit()
# Step 2: Invalidate cache (delete, don't update)
cache.delete(f"product:{product_id}")
Why Invalidate Instead of Update
On writes, cache-aside deletes the cache entry rather than updating it. This is deliberate. If two concurrent writes update the cache, a race condition can leave the cache holding stale data:
Thread A: UPDATE database → price = 100
Thread B: UPDATE database → price = 200
Thread A: SET cache → price = 100 (stale!)
Thread B: SET cache → price = 200
If Thread A’s cache write executes after Thread B’s, the cache holds the stale value. By deleting instead of updating, the next read always fetches the current value from the database. This pattern trades a single cache miss for guaranteed consistency.
Cache-Aside Trade-Offs
Advantages:
- The application has full control over what gets cached and when
- Cache failures do not affect writes — the database is always the source of truth
- Only data that is actually read gets cached, avoiding wasted memory on unused entries
Disadvantages:
- Every cache miss incurs the full database query latency — the first request after invalidation is always slow
- The application code is responsible for all cache logic, which can lead to inconsistent caching behavior across different parts of the codebase
- Stale data is possible during the window between a database write and cache invalidation
Cache-aside works best for read-heavy workloads where occasional stale data during short windows is acceptable. For applications already using Redis beyond simple caching, cache-aside is a natural extension of existing Redis usage patterns.
Read-Through
Read-through looks similar to cache-aside from the application’s perspective, but the cache layer itself is responsible for fetching data from the database on a miss. The application always reads from the cache — it never queries the database directly for cached data.
How Read-Through Works
Read path:
- Application requests data from the cache
- If found, the cache returns it
- If not found, the cache queries the database, stores the result, and returns it
Write path: Read-through does not define a write strategy — it is typically paired with write-through or write-behind for writes.
class ReadThroughCache:
def __init__(self, redis_client, db_connection, default_ttl=3600):
self.cache = redis_client
self.db = db_connection
self.ttl = default_ttl
def get(self, cache_key: str, db_query: str, params: tuple) -> Optional[dict]:
# Always try cache first
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# Cache handles the database fetch internally
result = self.db.execute(db_query, params).fetchone()
if result is None:
# Cache the absence to prevent repeated DB hits (negative caching)
self.cache.setex(cache_key, 300, json.dumps(None))
return None
result_dict = dict(result)
self.cache.setex(cache_key, self.ttl, json.dumps(result_dict))
return result_dict
# Application code becomes simpler
read_cache = ReadThroughCache(cache, db)
def get_product(product_id: int) -> Optional[dict]:
return read_cache.get(
f"product:{product_id}",
"SELECT * FROM products WHERE id = %s",
(product_id,)
)
Negative Caching
Notice the negative caching pattern — when the database returns no result, the cache stores None with a shorter TTL. Without negative caching, repeated requests for nonexistent keys hit the database every time. This is a common attack vector: an attacker sends requests for IDs that do not exist, bypassing the cache and overwhelming the database.
Read-Through Trade-Offs
Advantages:
- Application code is simpler — it always reads from the cache, never directly from the database
- Caching logic is centralized in the cache layer, reducing inconsistencies across the codebase
- Negative caching is easier to implement systematically
Disadvantages:
- The cache layer needs to know how to query the database, which couples the cache to your data access layer
- The first read after invalidation is still slow (same cold-start problem as cache-aside)
- Most off-the-shelf Redis setups do not support read-through natively — you need to build the abstraction yourself or use a framework that provides it
Read-through is best when you want to centralize cache management and reduce the chance of developers implementing caching inconsistently. Teams using Spring Boot often get read-through behavior from the @Cacheable annotation, which handles the cache-check-then-fetch pattern declaratively.
Write-Through
Write-through ensures that every write goes to both the cache and the database synchronously. The application writes to the cache, and the cache writes to the database before confirming the operation. As a result, the cache and database are always in sync.
How Write-Through Works
Write path:
- Application sends a write to the cache layer
- The cache writes to the database synchronously
- The cache updates its own entry
- The cache confirms the write to the application
Read path: Reads always hit the cache. Since writes keep the cache up to date, cache misses only occur for data that has never been accessed.
class WriteThroughCache:
def __init__(self, redis_client, db_connection, default_ttl=3600):
self.cache = redis_client
self.db = db_connection
self.ttl = default_ttl
def write(self, cache_key: str, data: dict, db_query: str, params: tuple):
# Step 1: Write to database first (source of truth)
self.db.execute(db_query, params)
self.db.commit()
# Step 2: Update cache (only after DB write succeeds)
self.cache.setex(cache_key, self.ttl, json.dumps(data))
def get(self, cache_key: str, db_query: str, params: tuple) -> Optional[dict]:
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
result = self.db.execute(db_query, params).fetchone()
if result:
result_dict = dict(result)
self.cache.setex(cache_key, self.ttl, json.dumps(result_dict))
return result_dict
return None
# Usage
wt_cache = WriteThroughCache(cache, db)
def update_product(product_id: int, name: str, price: float):
wt_cache.write(
cache_key=f"product:{product_id}",
data={"id": product_id, "name": name, "price": price},
db_query="UPDATE products SET name = %s, price = %s WHERE id = %s",
params=(name, price, product_id)
)
Write-Through Trade-Offs
Advantages:
- Cache and database are always consistent — no stale data window
- Reads are always fast because the cache is always populated after a write
- Data loss risk is minimal because the database write completes before the operation is confirmed
Disadvantages:
- Write latency increases because every write involves both the cache and the database sequentially
- Infrequently read data still gets cached, wasting memory on entries that may never be read before expiration
- If the cache write fails after the database write succeeds, the system still becomes inconsistent — you need error handling for this edge case
Write-through works best when data consistency is more important than write latency. Financial applications, inventory systems, and configuration management benefit from write-through because stale cached data in these domains causes real business problems.
Write-Behind (Write-Back)
Write-behind is the most aggressive caching strategy. The application writes to the cache, and the cache asynchronously flushes changes to the database in the background. This makes writes extremely fast because the application only waits for the cache write, not the database write.
How Write-Behind Works
Write path:
- Application writes to the cache
- The cache immediately confirms the write
- A background process batches cache changes and writes them to the database periodically
Read path: Identical to read-through — the cache always serves reads.
import threading
import time
from collections import deque
class WriteBehindCache:
def __init__(self, redis_client, db_connection, flush_interval=5):
self.cache = redis_client
self.db = db_connection
self.write_queue = deque()
self.lock = threading.Lock()
# Background thread flushes writes to database
self.flush_thread = threading.Thread(target=self._flush_loop, args=(flush_interval,), daemon=True)
self.flush_thread.start()
def write(self, cache_key: str, data: dict, db_query: str, params: tuple):
# Immediately update cache
self.cache.set(cache_key, json.dumps(data))
# Queue the database write for background processing
with self.lock:
self.write_queue.append({"query": db_query, "params": params})
def _flush_loop(self, interval: int):
while True:
time.sleep(interval)
self._flush_to_database()
def _flush_to_database(self):
with self.lock:
batch = list(self.write_queue)
self.write_queue.clear()
if not batch:
return
try:
for item in batch:
self.db.execute(item["query"], item["params"])
self.db.commit()
except Exception as e:
# Re-queue failed writes for retry
with self.lock:
self.write_queue.extendleft(reversed(batch))
log.error(f"Write-behind flush failed: {e}")
Write-Behind Trade-Offs
Advantages:
- Write latency is minimal because the application only waits for the in-memory cache write
- Database writes are batched, reducing the total number of database round-trips
- The database experiences smoother write patterns because bursts are absorbed by the cache and flushed gradually
Disadvantages:
- Data loss risk is real. If the cache crashes before flushing to the database, buffered writes are lost
- The cache temporarily holds data that the database does not have, making the cache the de facto source of truth during the buffer window
- Debugging is harder because the database may lag behind what the application sees
- Implementing reliable retry logic for failed flushes adds significant complexity
Write-behind is appropriate for use cases where write throughput matters more than immediate durability: analytics event collection, session state updates, activity logging, and metrics aggregation. It is not appropriate for financial transactions, order processing, or any data where loss is unacceptable.
Caching Strategies Comparison
| Strategy | Read Latency | Write Latency | Consistency | Data Loss Risk | Complexity |
|---|---|---|---|---|---|
| Cache-Aside | Miss: high, Hit: low | Low (DB only) | Eventual (short window) | None (DB is truth) | Low |
| Read-Through | Miss: high, Hit: low | N/A (pair with write strategy) | Depends on write strategy | None | Medium |
| Write-Through | Always low | Higher (DB + cache) | Strong | Minimal | Medium |
| Write-Behind | Always low | Very low (cache only) | Eventual (buffer window) | Yes (cache crash) | High |
This comparison table serves as a quick reference. However, the real decision depends on your specific data characteristics, which the next section addresses.
Choosing the Right Strategy by Use Case
User Profile Data
Recommended: Cache-aside with TTL
User profiles are read frequently but updated rarely. Cache-aside keeps popular profiles in cache without wasting memory on inactive users. A 1-hour TTL ensures that profile changes propagate within a reasonable window. Because profile staleness for an hour rarely causes business problems, the simplicity of cache-aside wins.
Product Catalog and Pricing
Recommended: Write-through
Price changes must reflect immediately — showing a customer a stale price and then charging a different amount at checkout causes trust issues and potential legal problems. Write-through guarantees that the cache always matches the database. The slightly higher write latency is acceptable because product updates happen far less frequently than product views.
Session State
Recommended: Write-behind with short flush interval
Session updates happen on nearly every request (last activity timestamp, page views, temporary preferences). Writing to the database on every request wastes throughput on data that is inherently ephemeral. Write-behind with a 5-second flush interval reduces database writes by an order of magnitude. If a cache failure loses the last 5 seconds of session state, the user simply re-authenticates — an acceptable trade-off.
Analytics Events
Recommended: Write-behind with batched flushes
Analytics events arrive at high volume and do not need immediate database persistence. Write-behind absorbs traffic spikes and writes to the database in efficient batches. Losing a few seconds of analytics data during a cache failure is rarely consequential.
Financial Transactions
Recommended: No caching on the write path
Cache financial transaction writes directly to the database with full ACID guarantees. For reads, cache-aside with short TTLs can serve balance lookups and transaction history, but the write path should never depend on a cache layer. The risk of data loss or inconsistency outweighs any latency improvement.
Cache Invalidation Patterns
Regardless of which caching strategy you choose, stale data eventually needs to be removed. Cache invalidation is famously described as one of the two hardest problems in computer science — and for good reason.
TTL-Based Expiration
The simplest invalidation strategy: every cache entry expires after a fixed time period. TTLs are a safety net that ensures stale data does not persist indefinitely, even if explicit invalidation fails.
# Short TTL for frequently changing data
cache.setex("stock_price:AAPL", 30, json.dumps(price_data)) # 30 seconds
# Long TTL for stable reference data
cache.setex("country:US", 86400, json.dumps(country_data)) # 24 hours
Choose TTLs based on how stale the data can be before it causes problems. Aggressive TTLs (seconds) keep data fresh but increase cache misses. Generous TTLs (hours) maximize hit rates but tolerate more staleness.
Event-Based Invalidation
When the database changes, publish an invalidation event that tells all application instances to delete the affected cache entries. Redis Pub/Sub provides a lightweight mechanism for this.
# Publisher: after updating the database
def invalidate_product_cache(product_id: int):
cache.delete(f"product:{product_id}")
cache.publish("cache_invalidation", json.dumps({
"type": "product",
"id": product_id,
}))
# Subscriber: on each application server
def handle_invalidation(message):
data = json.loads(message["data"])
if data["type"] == "product":
local_cache.pop(f"product:{data['id']}", None)
Event-based invalidation reduces the stale data window to the message propagation time (typically milliseconds). Combined with TTL-based expiration as a safety net, this approach handles both planned invalidation and edge cases where events get dropped.
Versioned Keys
Instead of invalidating cache entries, change the cache key when data updates. This avoids the race condition where a read repopulates the cache with stale data immediately after invalidation.
def get_product_with_version(product_id: int) -> dict:
# Get the current version for this product
version = cache.get(f"product_version:{product_id}") or "1"
cache_key = f"product:{product_id}:v{version}"
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
product = fetch_from_database(product_id)
cache.setex(cache_key, 3600, json.dumps(product))
return product
def update_product(product_id: int, updates: dict):
save_to_database(product_id, updates)
# Increment version — old cache entry becomes orphaned and expires via TTL
cache.incr(f"product_version:{product_id}")
Cache Stampede Prevention
A cache stampede occurs when a popular cache entry expires and hundreds of concurrent requests all experience a cache miss simultaneously. They all query the database at the same time, potentially overwhelming it.
Locking Pattern
Only one request fetches from the database while others wait for the cache to be repopulated.
def get_with_lock(cache_key: str, fetch_fn, ttl: int = 3600) -> Optional[dict]:
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
lock_key = f"lock:{cache_key}"
# Try to acquire a lock (expires in 10 seconds to prevent deadlock)
acquired = cache.set(lock_key, "1", nx=True, ex=10)
if acquired:
try:
# This request fetches from the database
result = fetch_fn()
if result:
cache.setex(cache_key, ttl, json.dumps(result))
return result
finally:
cache.delete(lock_key)
else:
# Another request is fetching — wait briefly and retry from cache
time.sleep(0.1)
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
# Fallback: fetch from database if the lock holder failed
return fetch_fn()
Early Expiration
Refresh cache entries before they actually expire. Set an internal “soft expiry” that is shorter than the TTL. When a request sees data past the soft expiry, it refreshes the cache in the background while still returning the slightly stale cached data.
def get_with_early_refresh(cache_key: str, fetch_fn, ttl: int = 3600, soft_ttl: int = 3000):
raw = cache.get(cache_key)
if raw:
entry = json.loads(raw)
if time.time() < entry["soft_expires"]:
return entry["data"]
# Soft-expired: return stale data but trigger background refresh
threading.Thread(target=_refresh_cache, args=(cache_key, fetch_fn, ttl, soft_ttl)).start()
return entry["data"]
# Hard miss
return _refresh_cache(cache_key, fetch_fn, ttl, soft_ttl)
def _refresh_cache(cache_key, fetch_fn, ttl, soft_ttl):
result = fetch_fn()
if result:
entry = {"data": result, "soft_expires": time.time() + soft_ttl}
cache.setex(cache_key, ttl, json.dumps(entry))
return result
This pattern eliminates stampedes entirely because cache entries never fully expire under load. The background refresh keeps data fresh while the slightly stale entry absorbs concurrent requests.
Real-World Scenario: Evolving Caching Strategies in a Growing E-Commerce Platform
A mid-sized e-commerce platform serves roughly 200,000 daily active users. Initially, the team runs without any caching — the PostgreSQL database handles all reads. As traffic grows, product page load times increase from 150ms to 600ms during peak hours. Database performance tuning helps temporarily, but the team recognizes that caching is the long-term solution.
Phase 1: Cache-aside for product data. The team adds Redis cache-aside for product listings and detail pages. Cache hit rates reach 85% within the first week, and average page load times drop back to 180ms. The implementation takes two days — straightforward get from cache, if miss fetch from DB, store in cache logic wrapped in a utility function.
Phase 2: Write-through for pricing. After a pricing incident where a cached product displayed a sale price for 45 minutes after the sale ended, the team switches pricing data to write-through caching. Every price update now writes to both the database and cache synchronously. This adds approximately 3ms to each price update — negligible given that price changes happen a few hundred times per day, not thousands of times per second.
Phase 3: Write-behind for user activity. The recommendation engine needs recent user browsing data (products viewed, search queries, time spent on pages). Writing every page view to the database generates thousands of writes per second during peak traffic. The team implements write-behind caching: user activity events write to Redis immediately and flush to the database in 10-second batches. Database write volume drops by 90%.
Phase 4: Cache stampede prevention. During a flash sale, the homepage product grid’s cache entry expires, and 2,000 concurrent requests all hit the database simultaneously. The database connection pool exhausts, and the homepage returns errors for roughly 8 seconds. The team adds the locking pattern for high-traffic cache keys and early expiration for the homepage cache. Subsequent sales events show no cache-related issues.
The key insight from this progression is that no single caching strategy fits all data types. The team ended up using three different strategies for three different data characteristics, and each addition addressed a specific problem rather than a theoretical concern.
When to Use Caching Strategies
- Your application has a read-to-write ratio above 10:1 for specific data — caching shines when reads dominate
- Database query latency affects user experience and simpler optimizations (indexing, query tuning) have been applied
- The same data is read repeatedly by multiple users or requests (product pages, configuration, reference data)
- You need to absorb traffic spikes without proportionally scaling your database
When NOT to Cache
- Your data changes on every read (real-time stock tickers, live auction bids) — the invalidation overhead exceeds the caching benefit
- Your application already responds within acceptable latency without caching — adding cache adds complexity without meaningful improvement
- Strong consistency is required and eventual consistency cannot be tolerated for any duration
- The data is unique per request (personalized search results with no overlap between users) — cache hit rates will be too low to justify the memory cost
Common Mistakes with Caching Strategies
- Using cache-aside for data where stale values cause business problems (prices, inventory counts) — write-through is the safer choice for these cases
- Implementing write-behind without a reliable retry mechanism for failed database flushes, leading to silent data loss
- Setting the same TTL for all cached data regardless of how frequently it changes or how stale it can safely be
- Not implementing negative caching, allowing requests for nonexistent keys to bypass the cache and hit the database on every attempt
- Caching too aggressively during development, making bugs harder to reproduce because the cache masks database issues
- Ignoring cache stampedes until a high-traffic event triggers one — the locking or early expiration pattern should be in place before you need it
- Treating the cache as the source of truth instead of the database — the cache is a performance optimization, not a primary data store (unless you have explicitly chosen write-behind and accept the trade-offs)
Completing the Caching Strategies Overview
Choosing the right caching strategies comes down to understanding your data’s consistency requirements and access patterns. Cache-aside provides the simplest starting point for read-heavy data. Write-through guarantees consistency when stale data causes business problems. Write-behind maximizes write throughput for data where eventual persistence is acceptable. Most production systems use a combination of strategies — different data types have different characteristics, and applying a single strategy uniformly leads to either unnecessary complexity or unacceptable staleness.
Start with cache-aside for your most-read data, measure the impact, and evolve your caching strategies as specific data types reveal their consistency and throughput requirements. The best caching architecture is one where each data type is cached with the strategy that matches its actual access pattern, not one where every cache entry follows the same rules.