Eventually, every growing application hits a point where a single database server cannot keep up. Queries slow down, write throughput plateaus, and storage approaches the limits of what a single machine can offer. Database sharding — splitting your data across multiple database instances — is one of the most powerful solutions to this scaling ceiling, and also one of the most complex to implement correctly.
The complexity is why database sharding should be your last resort, not your first optimization. Before distributing data across multiple servers, you should exhaust single-instance optimizations: proper indexing strategies, query optimization, connection pooling, read replicas, and caching. However, when those measures are no longer sufficient, understanding how to shard effectively becomes essential.
This deep dive covers the two fundamental partitioning strategies — horizontal and vertical — along with shard key selection, routing patterns, rebalancing, and the operational complexity that comes with distributing your data layer.
What Database Sharding Actually Means
Database sharding is a specific form of horizontal partitioning where data is distributed across multiple independent database instances (shards), each running on its own server. Every shard holds a subset of the total data and operates independently. Together, the shards contain the complete dataset.
The key distinction from replication is that sharding splits data, while replication copies it. A replicated database has multiple copies of the same data for read scalability and failover. A sharded database distributes different data to different servers for both read and write scalability.
Why sharding works: If a single database handles 10,000 writes per second and you shard across 4 servers, each server handles approximately 2,500 writes per second. Similarly, if a single server stores 2 TB and you shard across 4 servers, each stores roughly 500 GB. Both the throughput ceiling and the storage ceiling scale linearly with the number of shards.
Why sharding is hard: Your application now needs to know which shard holds the data it needs. Queries that previously hit one database might now need to query multiple shards and merge results. Transactions that span multiple shards become significantly more complex. These costs are real and permanent — once you shard, the complexity does not go away.
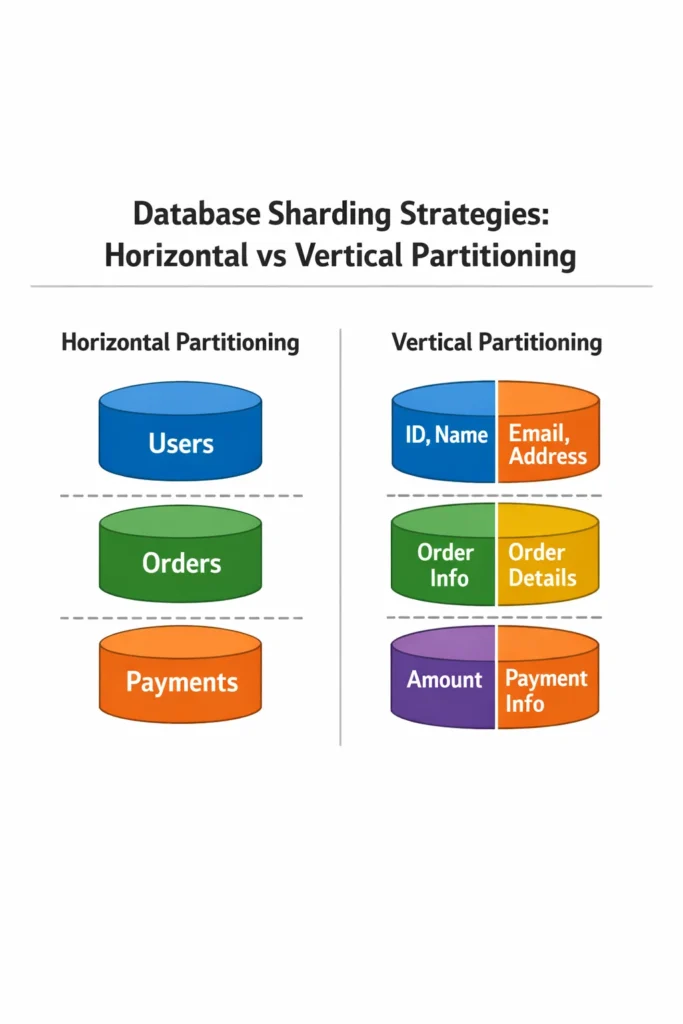
Horizontal Partitioning vs Vertical Partitioning
These two strategies split data along different axes. Understanding the difference is fundamental before choosing a sharding approach.
Horizontal Partitioning (Row-Based)
Horizontal partitioning distributes rows of the same table across multiple shards. Each shard has the same table schema but holds a different subset of rows. For example, a users table with 100 million rows might be split so that Shard 1 holds users 1-25 million, Shard 2 holds 25-50 million, and so on.
Shard 1: users table (user_id 1 - 25,000,000)
Shard 2: users table (user_id 25,000,001 - 50,000,000)
Shard 3: users table (user_id 50,000,001 - 75,000,000)
Shard 4: users table (user_id 75,000,001 - 100,000,000)
When horizontal partitioning fits: Your tables have many rows but a manageable number of columns. Most queries access a small subset of rows that can be identified by a shard key. This is the most common form of database sharding in production.
Vertical Partitioning (Column-Based)
Vertical partitioning splits a table by columns, moving different column groups to different databases. For example, a users table might keep core profile data (name, email, password) in one database and extended profile data (bio, preferences, avatar URL) in another.
Database A: users_core (user_id, email, password_hash, created_at)
Database B: users_profile (user_id, display_name, bio, avatar_url, preferences)
Database C: users_activity (user_id, last_login, session_count, feature_flags)
When vertical partitioning fits: Your table has many columns with different access patterns. Core columns are read on every request, while extended columns are read occasionally. Splitting them reduces the I/O footprint of frequent queries. Additionally, vertical partitioning aligns naturally with microservice boundaries — the auth service owns users_core, the profile service owns users_profile.
Combining Both Strategies
Large systems often use both strategies. First, vertically partition by domain (separate databases for users, orders, and analytics). Then, horizontally shard the tables that grow largest within each domain. An e-commerce platform might vertically separate orders from product catalog, then horizontally shard the orders table by customer ID.
Shard Key Selection: The Most Critical Decision
The shard key determines which shard holds each piece of data. A poor shard key choice can make database sharding worse than useless — it can create hotspots that overload some shards while others sit idle, or it can force every query to hit every shard because the application cannot determine which shard has the needed data.
Properties of a Good Shard Key
High cardinality: The key should have many distinct values to distribute data evenly. Sharding by country code puts most data on a few shards (US, India, China) while leaving hundreds of shards nearly empty.
Even distribution: The key’s values should be roughly uniformly distributed. Auto-incrementing IDs work well because new IDs spread evenly across shards. Timestamps do not — all recent data lands on the same shard, creating a write hotspot.
Query alignment: Most queries should include the shard key, allowing the router to direct the query to a single shard. If your most common query filters by user_id, then user_id is a natural shard key. If your most common query filters by created_at, sharding by user_id forces every time-range query to hit all shards.
Common Shard Key Strategies
Hash-based sharding: Apply a hash function to the shard key and use modulo to determine the shard number.
import hashlib
def get_shard(user_id: int, num_shards: int) -> int:
# Consistent hashing avoids full redistribution when adding shards
hash_value = int(hashlib.md5(str(user_id).encode()).hexdigest(), 16)
return hash_value % num_shards
# Example: user 12345 goes to shard 2 (out of 4)
shard = get_shard(12345, 4)
Advantages: Distributes data uniformly regardless of the key’s natural distribution. New IDs and old IDs spread across shards equally.
Disadvantages: Range queries become expensive. Finding “all users created this month” requires querying every shard because the hash destroys the natural ordering. Furthermore, adding or removing shards redistributes a large fraction of the data unless you use consistent hashing.
Range-based sharding: Assign contiguous ranges of the shard key to each shard.
SHARD_RANGES = [
(0, 25_000_000, "shard-1.db.internal"),
(25_000_001, 50_000_000, "shard-2.db.internal"),
(50_000_001, 75_000_000, "shard-3.db.internal"),
(75_000_001, 100_000_000, "shard-4.db.internal"),
]
def get_shard_range(user_id: int) -> str:
for low, high, host in SHARD_RANGES:
if low <= user_id <= high:
return host
raise ValueError(f"No shard found for user_id {user_id}")
Advantages: Range queries on the shard key are efficient — “all users with IDs 30M-35M” hits only Shard 2. Additionally, adding a new shard for the newest range is straightforward because existing shards remain untouched.
Disadvantages: Data skew is common. If newer users are more active, the latest shard receives disproportionate write traffic. Range-based sharding requires manual monitoring and periodic rebalancing.
Directory-based sharding: Maintain a lookup table that maps each shard key to a shard. The routing layer queries this directory before every data access.
import redis
directory = redis.Redis(host='shard-directory.internal', port=6379)
def get_shard_directory(user_id: int) -> str:
shard = directory.get(f"shard:{user_id}")
if shard is None:
# New user: assign to the least-loaded shard
shard = assign_to_least_loaded_shard(user_id)
directory.set(f"shard:{user_id}", shard)
return shard.decode()
Advantages: Maximum flexibility — you can move individual keys between shards without changing the sharding logic. Rebalancing becomes a matter of updating directory entries and migrating the actual data.
Disadvantages: The directory itself becomes a critical dependency and potential bottleneck. Every data access requires a directory lookup, adding latency. Cache the directory aggressively to mitigate this.
Shard Key Examples by Domain
| Domain | Recommended Shard Key | Reasoning |
|---|---|---|
| Social media | user_id | Most queries are user-centric (my feed, my posts, my messages) |
| E-commerce | customer_id | Orders, cart, and history are per-customer |
| Multi-tenant SaaS | tenant_id | All tenant data co-located on the same shard |
| Analytics | event_date | Time-range queries are the primary access pattern |
| Gaming | game_session_id | Session data is accessed together during gameplay |
For multi-tenant SaaS applications, tenant_id is almost always the right shard key because it guarantees that all of a tenant’s data lives on the same shard. This makes single-tenant queries fast and avoids cross-shard joins entirely.
Routing: Getting Requests to the Right Shard
Once data is distributed, every query needs to reach the correct shard. Three routing patterns exist.
Application-Level Routing
The application code includes shard-aware logic that determines the target shard before executing queries.
from sqlalchemy import create_engine
# Connection pool per shard
shard_engines = {
0: create_engine("postgresql://shard0.db.internal/app"),
1: create_engine("postgresql://shard1.db.internal/app"),
2: create_engine("postgresql://shard2.db.internal/app"),
3: create_engine("postgresql://shard3.db.internal/app"),
}
def get_engine(user_id: int) -> Engine:
shard_id = get_shard(user_id, len(shard_engines))
return shard_engines[shard_id]
def get_user(user_id: int):
engine = get_engine(user_id)
with engine.connect() as conn:
result = conn.execute(
text("SELECT * FROM users WHERE id = :id"),
{"id": user_id}
)
return result.fetchone()
Managing connection pools across multiple database instances requires careful configuration. Each shard gets its own connection pool, so the total number of connections from your application to the database tier multiplies by the number of shards.
Proxy-Level Routing
A database proxy (like Vitess for MySQL or Citus for PostgreSQL) sits between the application and the shards. The application sends queries to the proxy as if it were a single database, and the proxy routes them to the correct shard.
Advantages: The application code does not need shard-aware logic. The proxy handles routing, cross-shard queries, and even schema migrations across shards.
Disadvantages: The proxy adds latency and becomes another critical infrastructure component to operate. However, for teams adopting database sharding for the first time, a proxy significantly reduces application complexity.
Data-Layer Routing
Some databases handle sharding natively. MongoDB’s built-in sharding, CockroachDB’s range-based partitioning, and Cassandra’s consistent hashing all route queries internally without application or proxy changes.
When this fits: You are choosing a database from scratch and sharding is a known requirement. Adopting a natively sharded database avoids the operational burden of managing sharding logic yourself.
Cross-Shard Queries and Joins
The most painful consequence of database sharding is that queries spanning multiple shards become complex and slow. A query like “find all orders over $100 placed this week” needs to hit every shard if the data is sharded by customer ID.
Scatter-Gather Pattern
Send the query to all shards in parallel, then merge the results in the application layer.
import asyncio
from typing import Any
async def scatter_gather_query(query: str, params: dict) -> list[Any]:
async def query_shard(shard_id: int):
engine = shard_engines[shard_id]
async with engine.connect() as conn:
result = await conn.execute(text(query), params)
return result.fetchall()
# Query all shards in parallel
tasks = [query_shard(i) for i in range(len(shard_engines))]
shard_results = await asyncio.gather(*tasks)
# Merge results
all_rows = []
for rows in shard_results:
all_rows.extend(rows)
return all_rows
Scatter-gather works but scales poorly. If you have 16 shards, every cross-shard query generates 16 database queries. Consequently, minimize the need for cross-shard queries by choosing shard keys that align with your most common access patterns.
Denormalization to Avoid Cross-Shard Joins
If you frequently need to join orders with product names, and orders are sharded by customer ID while products live in a separate database, consider denormalizing product names into the orders table. This duplicates data but eliminates the cross-shard join.
-- Instead of joining with products table on another shard
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
customer_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
product_name VARCHAR(255) NOT NULL, -- Denormalized from products table
product_price DECIMAL(10, 2) NOT NULL, -- Denormalized
quantity INT NOT NULL,
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
The trade-off is that updates to product names need to propagate to all order records. For data that changes infrequently (product names, category labels), denormalization is a practical compromise. For data that changes frequently, maintain a separate read-optimized view instead.
Cross-Shard Transactions
Transactions that span multiple shards require two-phase commit (2PC) or saga patterns, both of which add significant complexity and latency. Understanding transaction isolation levels within a single database is already nuanced — distributing transactions across shards amplifies every edge case.
The practical advice: design your shard key so that transactions stay within a single shard whenever possible. If a business operation must modify data on two shards, consider whether eventual consistency (using events and sagas) is acceptable rather than requiring strict transactional guarantees.
Rebalancing: Adding and Removing Shards
As data grows, you will eventually need to add shards. Rebalancing — redistributing data across the new shard topology — is one of the most operationally demanding aspects of database sharding.
The Problem with Naive Hash Modulo
If you use hash(key) % num_shards, adding a shard changes the modulo result for nearly every key. Going from 4 shards to 5 shards reassigns roughly 80% of keys to different shards, requiring massive data migration.
Consistent Hashing
Consistent hashing maps both keys and shards onto a hash ring. When a shard is added, only the keys between the new shard and its neighbor need to move — roughly 1/N of the total data (where N is the number of shards).
import hashlib
from bisect import bisect_right
class ConsistentHashRing:
def __init__(self, replicas: int = 150):
self.replicas = replicas # Virtual nodes per shard
self.ring = [] # Sorted list of (hash_position, shard_id)
self.shard_map = {}
def add_shard(self, shard_id: str):
for i in range(self.replicas):
hash_key = f"{shard_id}:replica:{i}"
position = int(hashlib.md5(hash_key.encode()).hexdigest(), 16)
self.ring.append((position, shard_id))
self.ring.sort()
def get_shard(self, key: str) -> str:
if not self.ring:
raise ValueError("No shards available")
hash_value = int(hashlib.md5(str(key).encode()).hexdigest(), 16)
# Find the first shard position >= hash_value
positions = [pos for pos, _ in self.ring]
idx = bisect_right(positions, hash_value) % len(self.ring)
return self.ring[idx][1]
Virtual nodes (replicas in the code above) ensure even distribution. Without them, shards placed unevenly on the ring can create hotspots. With 150 virtual nodes per shard, the data distribution becomes nearly uniform.
Live Rebalancing Strategy
Adding a shard to a live system requires migrating data without downtime. The typical approach:
- Add the new shard to the ring but mark it as “catching up”
- Dual-write: New writes go to both the old shard (current owner) and the new shard (future owner)
- Background migration: Copy existing data from old shards to the new shard
- Verify: Confirm the new shard has all the data it should own
- Switch reads: Update the routing layer to read from the new shard for its key range
- Stop dual-write: Remove the old shard from responsibility for the migrated keys
- Clean up: Delete migrated data from old shards
This process requires careful coordination and is typically scripted and tested extensively before running in production. Running database migrations in production is already complex with a single database — sharding multiplies the coordination required.
Real-World Scenario: Sharding a Growing SaaS Platform
A B2B analytics platform stores event data for its customers. Each customer sends between 1,000 and 10 million events per day. The platform has roughly 500 customers generating a combined 2 billion events per month. The single PostgreSQL instance — a powerful machine with 64 cores, 512 GB RAM, and NVMe storage — starts showing strain. Query latency for large customers degrades during peak hours, and the storage is approaching 8 TB.
The team evaluates their options. Read replicas would help with query load but not with write throughput or storage. Vertical partitioning does not fit because the events table is already lean — every column is needed for every query. Horizontal sharding by customer_id aligns perfectly with the access pattern: every query filters by customer, and cross-customer queries never happen in the application.
They implement hash-based sharding with consistent hashing across 8 shards. Each shard gets a dedicated PostgreSQL instance. The routing logic lives in the application layer, using a library that maps customer IDs to shards.
The migration takes three weeks: one week to set up the infrastructure and dual-write logic, one week to migrate existing data while the system remains live, and one week of monitoring before decommissioning the old single instance. The most unexpected challenge is connection management — with 8 shards, the application opens 8 times as many database connections, which requires tuning the connection pool settings for each shard and adding PgBouncer in front of each instance.
After sharding, query latency drops by roughly 60% for large customers because each shard indexes a much smaller dataset. Write throughput headroom increases from nearly saturated to approximately 25% utilization per shard. The team plans to add shards incrementally as customer count grows, relying on consistent hashing to minimize data migration each time.
When to Use Database Sharding
- Your single database instance has reached its write throughput ceiling despite optimization
- Storage requirements exceed what a single server can practically handle
- You need to isolate tenant data for compliance or performance reasons (shard per tenant)
- Read replicas, caching, and query optimization have already been exhausted
- Your access patterns align naturally with a shard key (most queries filter by the same field)
When NOT to Use Database Sharding
- Your database performance problems can be solved with better indexes, query optimization, or PostgreSQL performance tuning — always optimize the single instance first
- Your application relies heavily on cross-table joins that would span shards — sharding would make these joins dramatically more expensive
- You have fewer than 100 million rows and moderate write throughput — a single well-tuned database handles this comfortably
- Your team lacks the operational experience to manage multiple database instances, connection pools, and migration tooling
- You can achieve sufficient scaling with read replicas and caching alone
Common Mistakes with Database Sharding
- Sharding too early, before exhausting single-instance optimizations — the complexity cost of sharding is permanent, and premature sharding is one of the most expensive architectural decisions to reverse
- Choosing a shard key based on the data model rather than the query patterns, leading to frequent cross-shard queries that negate the performance benefits
- Using naive modulo hashing without consistent hashing, which causes massive data redistribution every time you add or remove a shard
- Ignoring the connection pool multiplication effect — 4 shards with 50 connections each means 200 total connections from the application tier, which can exceed database limits
- Not planning for rebalancing before the first shard addition is needed — building the migration tooling under pressure leads to shortcuts and data loss risks
- Assuming that all shards will have equal load — in practice, some customers or data ranges are always hotter than others, requiring monitoring and occasional manual rebalancing
- Neglecting schema changes across shards — adding a column to one shard but not others creates inconsistencies that are difficult to debug
Completing the Database Sharding Design
Database sharding trades application simplicity for horizontal scalability. The core decisions are choosing between horizontal and vertical partitioning (or combining both), selecting a shard key that aligns with your query patterns, and implementing a routing mechanism that directs each request to the correct shard. Consistent hashing makes adding shards manageable, and denormalization reduces the need for cross-shard joins.
The most important takeaway about database sharding is knowing when not to do it. Sharding introduces permanent operational complexity — connection management, cross-shard queries, distributed transactions, and rebalancing logistics. Exhaust every single-instance optimization first. When you do need to shard, choose the simplest shard key that eliminates cross-shard queries for your most common access patterns, and build the rebalancing tooling before you need it.