Most codebases do not fail because of bad algorithms or poor framework choices. They fail because the code does not reflect how the business actually works. Over time, developers build features using technical terminology that drifts further from what stakeholders mean, creating a translation gap that causes bugs, miscommunication, and modules that fight each other instead of working together.
Domain-driven design (DDD) addresses this problem by making the business domain the central organizing principle of your software. Instead of structuring code around technical layers (controllers, services, repositories), DDD structures code around business concepts (orders, payments, shipments) and the rules that govern them. The result is software where the code reads like a description of the business, making it easier to understand, modify, and discuss with non-technical stakeholders.
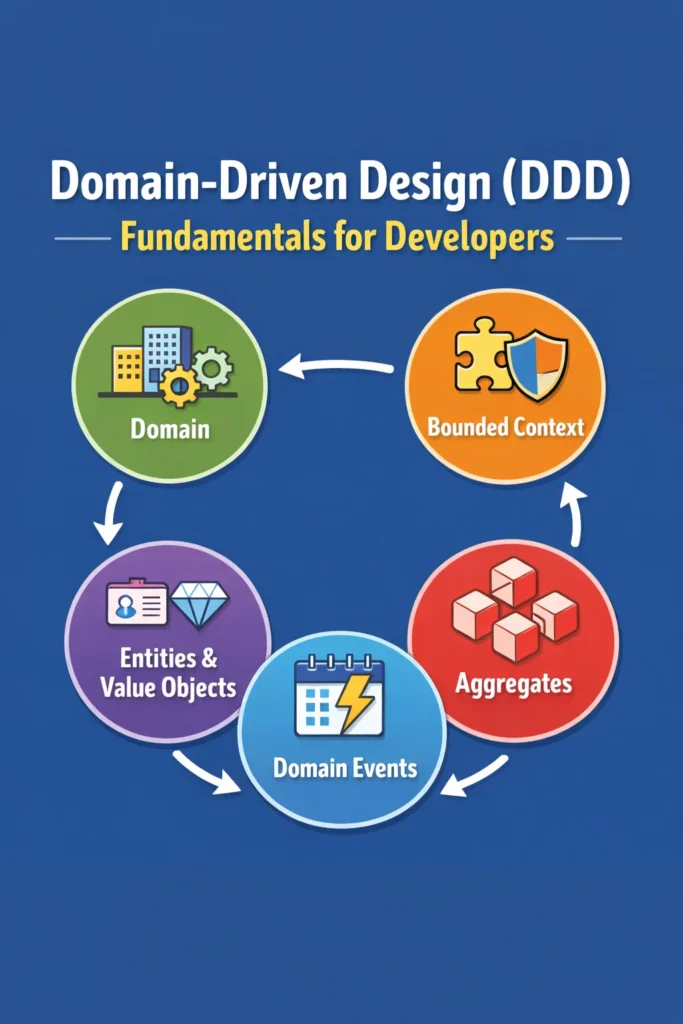
This foundational guide covers the core domain-driven design concepts that every developer should understand: ubiquitous language, bounded contexts, entities, value objects, and aggregates. These concepts apply regardless of whether you are building a monolith or microservices.
Ubiquitous Language: The Foundation of DDD
Ubiquitous language is the shared vocabulary between developers and domain experts. Every term has one precise meaning that both sides agree on, and that same terminology appears in conversations, documentation, and code.
Why Language Matters More Than You Think
Consider an e-commerce system. The marketing team calls it a “promotion,” the product team calls it a “discount,” and the database schema calls it a price_modifier. When a bug report says “the promotion isn’t applying,” three teams waste time figuring out whether they are even talking about the same thing.
In domain-driven design, the team agrees on a single term — say, “discount rule” — and uses it everywhere:
// The code uses the same language as the business
class DiscountRule {
constructor(
public readonly id: string,
public readonly name: string,
public readonly percentage: number,
public readonly validFrom: Date,
public readonly validUntil: Date,
public readonly applicableCategories: string[]
) {}
isActive(now: Date): boolean {
return now >= this.validFrom && now <= this.validUntil;
}
appliesTo(productCategory: string): boolean {
return this.applicableCategories.includes(productCategory);
}
}
Notice that the class name, method names, and property names all use business language. A product manager reading this code understands what it does without needing a developer to translate. This alignment is not cosmetic — it prevents the category of bugs that arise when the code’s mental model diverges from the business’s mental model.
Building Ubiquitous Language in Practice
- Hold modeling sessions with domain experts and developers in the same room
- When someone uses a term that others interpret differently, stop and define it explicitly
- Reject technical jargon in domain discussions — if the business does not use the term “DTO” or “repository,” neither should the domain model
- Update the language when the business evolves — terms that made sense last year might be misleading now
Bounded Contexts: Drawing the Boundaries
A bounded context is a boundary within which a particular domain model applies. Different parts of the business often use the same word to mean different things. In domain-driven design, each bounded context gets its own model where terms have precise, unambiguous meanings.
The Same Word, Different Meanings
In an e-commerce platform, “product” means different things to different teams:
- Catalog context: A product has a name, description, images, and categories
- Inventory context: A product has a SKU, warehouse location, and quantity on hand
- Pricing context: A product has a base price, discount rules, and tax classification
- Shipping context: A product has weight, dimensions, and shipping restrictions
Forcing all of these into a single Product class creates a monster object with dozens of fields, where changes for one team break functionality for another. Bounded contexts solve this by giving each context its own Product model with only the fields it needs.
// Catalog context — focused on display
class CatalogProduct {
constructor(
public readonly id: string,
public readonly name: string,
public readonly description: string,
public readonly imageUrls: string[],
public readonly category: string
) {}
}
// Inventory context — focused on stock management
class InventoryItem {
constructor(
public readonly productId: string,
public readonly sku: string,
public readonly warehouseId: string,
private quantity: number
) {}
reserve(amount: number): boolean {
if (this.quantity < amount) return false;
this.quantity -= amount;
return true;
}
restock(amount: number): void {
this.quantity += amount;
}
}
Each bounded context owns its data and its rules. The catalog context does not know about inventory quantities, and the inventory context does not know about product descriptions. They communicate through well-defined interfaces — typically events or APIs — rather than sharing a database.
Bounded Contexts and Microservices
Bounded contexts map naturally to microservice boundaries. Each microservice owns one bounded context, with its own database, its own model, and its own ubiquitous language. When migrating from a monolith to microservices, identifying bounded contexts is the first step in deciding where to split.
However, bounded contexts are not microservices. A monolithic application can contain multiple bounded contexts separated by modules or packages. The boundary is logical, not physical. Starting with well-defined bounded contexts inside a monolith makes a future microservices migration significantly smoother because the boundaries already exist.
Entities and Value Objects
Within a bounded context, domain-driven design distinguishes between two types of domain objects based on how they derive identity.
Entities: Identity Matters
An entity is an object defined by its identity rather than its attributes. Two customers with the same name and email are still different customers because they have different IDs. Entities persist over time and can change their attributes while remaining the same entity.
class Customer {
constructor(
public readonly id: string,
private name: string,
private email: string,
private shippingAddress: Address
) {}
updateEmail(newEmail: string): void {
// Business rule: email changes require verification
if (!isValidEmail(newEmail)) {
throw new Error("Invalid email format");
}
this.email = newEmail;
}
relocate(newAddress: Address): void {
this.shippingAddress = newAddress;
}
}
A customer who changes their email and address is still the same customer — identity is preserved through the id, not the attributes.
Value Objects: Attributes Matter
A value object is defined entirely by its attributes. Two Address objects with the same street, city, and zip code are interchangeable — there is no separate “address ID” that distinguishes them. Value objects are immutable: instead of modifying an address, you create a new one.
class Address {
constructor(
public readonly street: string,
public readonly city: string,
public readonly state: string,
public readonly zipCode: string,
public readonly country: string
) {}
equals(other: Address): boolean {
return (
this.street === other.street &&
this.city === other.city &&
this.state === other.state &&
this.zipCode === other.zipCode &&
this.country === other.country
);
}
}
class Money {
constructor(
public readonly amount: number,
public readonly currency: string
) {}
add(other: Money): Money {
if (this.currency !== other.currency) {
throw new Error("Cannot add different currencies");
}
return new Money(this.amount + other.amount, this.currency);
}
multiply(factor: number): Money {
return new Money(this.amount * factor, this.currency);
}
}
Why this distinction matters: Value objects eliminate a large category of bugs. When Money is a value object instead of a plain number, you cannot accidentally add dollars to euros. When Address is immutable, you cannot have two customers accidentally sharing and mutating the same address reference.
Common Misconception
Not everything with an ID in your database is an entity in domain-driven design terms. A database primary key exists for relational purposes, but the domain might treat the object as a value object. Ask this question: if two objects have identical attributes but different database IDs, does the business consider them the same thing? If yes, it is a value object. If no, it is an entity.
Aggregates: Consistency Boundaries
An aggregate is a cluster of entities and value objects that are treated as a single unit for data changes. Every aggregate has a root entity — the aggregate root — which is the only entry point for modifications to anything inside the aggregate.
Why Aggregates Exist
Without aggregates, any part of the code can modify any object at any time, making it impossible to enforce business rules consistently. Aggregates solve this by centralizing the enforcement of business invariants.
class Order {
private items: OrderItem[] = [];
private status: OrderStatus = OrderStatus.DRAFT;
constructor(
public readonly id: string,
public readonly customerId: string,
private readonly createdAt: Date
) {}
addItem(productId: string, quantity: number, unitPrice: Money): void {
if (this.status !== OrderStatus.DRAFT) {
throw new Error("Cannot modify a confirmed order");
}
const existing = this.items.find(i => i.productId === productId);
if (existing) {
existing.increaseQuantity(quantity);
} else {
this.items.push(new OrderItem(productId, quantity, unitPrice));
}
}
removeItem(productId: string): void {
if (this.status !== OrderStatus.DRAFT) {
throw new Error("Cannot modify a confirmed order");
}
this.items = this.items.filter(i => i.productId !== productId);
}
confirm(): void {
if (this.items.length === 0) {
throw new Error("Cannot confirm an empty order");
}
this.status = OrderStatus.CONFIRMED;
}
get total(): Money {
return this.items.reduce(
(sum, item) => sum.add(item.subtotal),
new Money(0, "USD")
);
}
}
The Order aggregate root controls all modifications to order items. External code cannot directly add items to the internal array or change the order status — it must go through the aggregate root’s methods, which enforce the business rules (cannot modify confirmed orders, cannot confirm empty orders).
Aggregate Design Rules
Keep aggregates small. An aggregate should contain only the entities and value objects needed to enforce a single set of business invariants. A common mistake is making the aggregate too large — including the customer, their orders, the order items, the products, and the inventory all in one aggregate. This creates lock contention and makes the system difficult to scale.
Reference other aggregates by ID, not by direct object reference. An Order stores customerId, not a Customer object. This keeps aggregates independent and allows them to live in different bounded contexts or even different databases.
One transaction per aggregate. Each database transaction should modify at most one aggregate. If a business operation needs to modify multiple aggregates, use domain events to coordinate between them asynchronously. This aligns with the eventual consistency model that CQRS and event sourcing build upon.
Real-World Scenario: Applying DDD to a Growing E-Commerce Monolith
A mid-sized e-commerce team with around 10 developers maintains a monolithic application. The codebase has grown to over 200,000 lines with a single shared database. Product changes frequently break order processing because the same Product model serves both the catalog and checkout. The team spends roughly a third of their sprint capacity on cross-team coordination to avoid breaking each other’s features.
The team introduces domain-driven design without rewriting the application. They start by identifying four bounded contexts: catalog, ordering, inventory, and payments. Within each context, they create separate models — the catalog’s Product has display fields, while ordering’s OrderLineItem has pricing and quantity. Shared database tables remain for now, but each context accesses only its own columns through dedicated repositories.
Over three months, cross-team conflicts drop significantly because each team modifies models within their own bounded context. New developers onboard faster because the code structure mirrors the business structure — finding where “discount rules” live requires looking in the pricing context, not searching through a flat service layer. The team later extracts the payment context into a separate service, and the extraction is straightforward because the bounded context boundary was already clean.
When to Apply Domain-Driven Design
- The business domain is complex with many interacting rules and concepts
- Multiple teams work on the same codebase and step on each other’s changes
- Stakeholders frequently report that the software “doesn’t work the way the business works”
- You are planning a monolith-to-microservices migration and need to identify service boundaries
When NOT to Apply Domain-Driven Design
- The application is a simple CRUD system with minimal business logic — DDD adds overhead without proportional benefit
- The team is very small (1-2 developers) and communication happens naturally without formal modeling
- The project is a short-lived prototype where long-term maintainability is not a priority
- Technical complexity (performance, infrastructure) outweighs domain complexity — DDD helps most when the business rules are the hard part
Common Mistakes with Domain-Driven Design
- Creating bounded contexts that mirror the technical architecture (frontend, backend, database) instead of the business domains — the boundaries should reflect business capabilities, not deployment units
- Making aggregates too large by including everything that is conceptually related, leading to lock contention and performance issues
- Skipping ubiquitous language and jumping straight to tactical patterns (entities, value objects) — the language alignment is where most of DDD’s value comes from
- Applying DDD patterns to every part of the application, including simple CRUD modules that do not have meaningful business logic
- Treating bounded contexts as shared libraries rather than independent models — contexts should not share domain classes, even if the classes look similar
- Not involving domain experts in modeling sessions, which produces a technically clean model that does not actually match how the business operates
Building on Domain-Driven Design
Domain-driven design gives you a vocabulary and a set of patterns for organizing code around business concepts. Ubiquitous language ensures everyone speaks the same language. Bounded contexts prevent a single model from becoming an unmanageable monolith. Entities and value objects classify domain objects by their identity semantics. Aggregates enforce consistency boundaries.
These fundamentals are the starting point, not the destination. As your system grows, domain-driven design patterns like domain events, CQRS, and the saga pattern build on top of these foundations. Start by identifying the bounded contexts in your current application and establishing a ubiquitous language with your domain experts. Even without restructuring any code, those two steps alone improve communication and reduce the bugs that come from misaligned mental models.