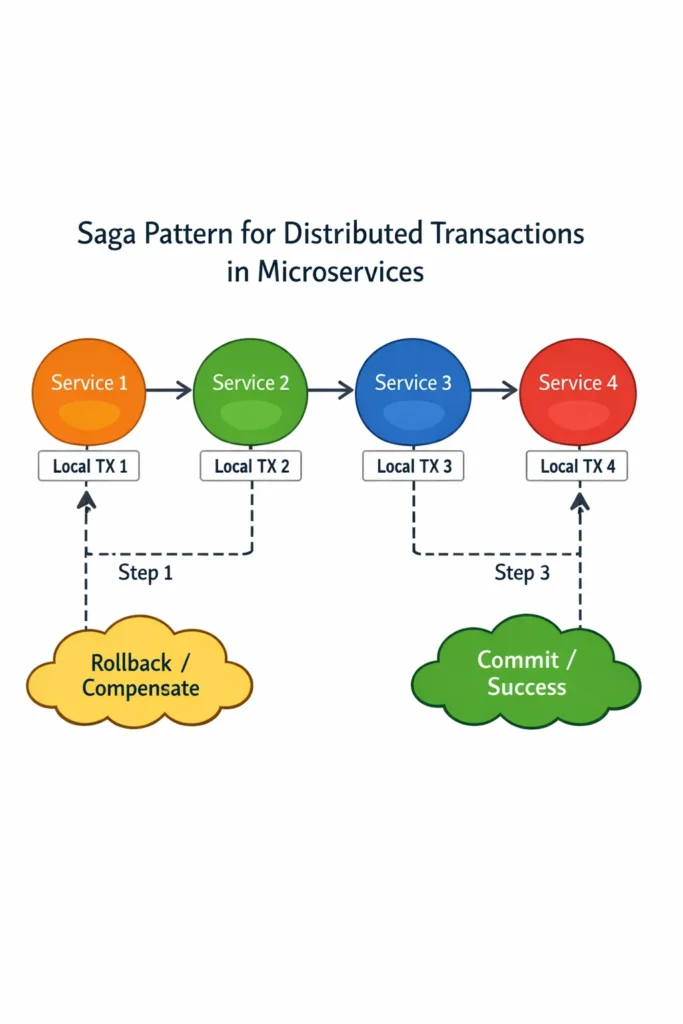
When a single business operation spans multiple microservices, you lose the safety net of database transactions. A monolith can wrap an order placement, payment charge, and inventory reservation in one ACID transaction — if any step fails, everything rolls back automatically. In a microservices architecture, each service owns its own database, so there is no single transaction boundary that covers the entire operation.
The saga pattern solves this by breaking a distributed transaction into a sequence of local transactions, each within a single service. If one step fails, the saga executes compensating transactions to undo the work completed by previous steps. Instead of an atomic rollback, you get an explicit undo sequence that achieves the same business outcome.
This deep dive covers both saga implementation styles — choreography and orchestration — with production code, compensation design, failure handling, and the trade-offs that determine which approach fits your system. Understanding transaction isolation within a single database provides useful context for why distributed transactions require a fundamentally different approach.
Why Traditional Transactions Do Not Work Across Services
In a monolithic application, you rely on ACID transactions to guarantee consistency. A single database connection wraps multiple operations in a transaction — either all succeed or all roll back.
# Monolith: single transaction across all operations
def place_order(order_data):
with db.transaction():
order = create_order(order_data)
charge_payment(order.total, order.customer_id)
reserve_inventory(order.items)
# If any step throws, the entire transaction rolls back
In microservices, each operation runs against a different database owned by a different service. There is no shared transaction coordinator. Two-phase commit (2PC) exists as a protocol for distributed transactions, but it has severe practical limitations:
- It blocks all participating services until every service confirms — a single slow or failed service blocks the entire transaction
- It requires all services to support the XA protocol, which many modern databases and message brokers do not
- It creates tight coupling between services, undermining the independence that motivated microservices in the first place
The saga pattern takes a different approach entirely: instead of trying to make multiple services behave like one transaction, it embraces eventual consistency and uses compensating actions to handle failures.
How the Saga Pattern Works
A saga consists of a series of steps, where each step is a local transaction within a single service. Each step also has a corresponding compensating transaction — an operation that semantically undoes the effect of the original step.
Consider an order placement saga with three services:
Happy path (all steps succeed):
- Order Service: Create order with status “pending”
- Payment Service: Charge the customer’s payment method
- Inventory Service: Reserve the ordered items
- Order Service: Update order status to “confirmed”
Failure path (inventory reservation fails):
- Order Service: Create order with status “pending” ✓
- Payment Service: Charge the customer ✓
- Inventory Service: Reserve items ✗ (out of stock)
- Compensation: Payment Service refunds the charge
- Compensation: Order Service marks order as “cancelled”
The compensating transactions run in reverse order, undoing each completed step. This achieves the same business outcome as a rollback, but through explicit operations rather than database-level undo mechanics.
Choreography-Based Sagas
In the choreography approach, each service listens for events and decides independently what to do next. There is no central coordinator — services react to events published by other services.
Event Flow
Order Service publishes → "OrderCreated"
↓
Payment Service listens, charges payment, publishes → "PaymentCompleted"
↓
Inventory Service listens, reserves items, publishes → "InventoryReserved"
↓
Order Service listens, confirms order, publishes → "OrderConfirmed"
Implementation
# order_service.py
from kafka import KafkaProducer, KafkaConsumer
import json
producer = KafkaProducer(
bootstrap_servers='kafka:9092',
value_serializer=lambda v: json.dumps(v).encode()
)
def create_order(order_data: dict) -> dict:
order = save_order_to_db(order_data, status="pending")
producer.send('order-events', value={
"type": "OrderCreated",
"order_id": order["id"],
"customer_id": order["customer_id"],
"items": order["items"],
"total": order["total"],
})
return order
# Listen for downstream events
def handle_saga_events():
consumer = KafkaConsumer(
'payment-events', 'inventory-events',
bootstrap_servers='kafka:9092',
group_id='order-service',
value_deserializer=lambda m: json.loads(m.decode())
)
for message in consumer:
event = message.value
if event["type"] == "InventoryReserved":
update_order_status(event["order_id"], "confirmed")
producer.send('order-events', value={
"type": "OrderConfirmed",
"order_id": event["order_id"],
})
elif event["type"] == "PaymentFailed":
update_order_status(event["order_id"], "cancelled")
elif event["type"] == "InventoryReservationFailed":
update_order_status(event["order_id"], "cancelled")
# Trigger payment refund
producer.send('payment-events', value={
"type": "RefundRequested",
"order_id": event["order_id"],
})
# payment_service.py
def handle_payment_events():
consumer = KafkaConsumer(
'order-events', 'payment-events',
bootstrap_servers='kafka:9092',
group_id='payment-service',
value_deserializer=lambda m: json.loads(m.decode())
)
for message in consumer:
event = message.value
if event["type"] == "OrderCreated":
try:
charge = process_payment(event["customer_id"], event["total"])
producer.send('payment-events', value={
"type": "PaymentCompleted",
"order_id": event["order_id"],
"charge_id": charge["id"],
})
except PaymentError as e:
producer.send('payment-events', value={
"type": "PaymentFailed",
"order_id": event["order_id"],
"reason": str(e),
})
elif event["type"] == "RefundRequested":
process_refund(event["order_id"])
producer.send('payment-events', value={
"type": "RefundCompleted",
"order_id": event["order_id"],
})
Choreography Trade-Offs
Advantages:
- No single point of failure — if one service goes down, others continue publishing and consuming events independently
- Services remain loosely coupled — each service only knows about the events it publishes and consumes
- Scales naturally with event-driven microservices because the event bus already exists
Disadvantages:
- The saga logic is scattered across multiple services, making it difficult to understand the complete flow
- Adding a new step requires modifying multiple services to handle new events
- Debugging failures is harder because there is no single place to inspect the saga’s current state
- Cyclic event dependencies can emerge as the system grows, creating implicit coupling that is difficult to detect
Orchestration-Based Sagas
In the orchestration approach, a central coordinator (the orchestrator) manages the saga’s execution. The orchestrator tells each service what to do and handles compensation when failures occur. Services do not need to know about each other — they only respond to commands from the orchestrator.
Command Flow
Saga Orchestrator → Payment Service: "ChargePayment"
← Payment Service: "PaymentCharged"
Saga Orchestrator → Inventory Service: "ReserveItems"
← Inventory Service: "ItemsReserved"
Saga Orchestrator → Order Service: "ConfirmOrder"
Implementation
# saga_orchestrator.py
import json
import uuid
from enum import Enum
from dataclasses import dataclass, field
class SagaStatus(Enum):
RUNNING = "running"
COMPLETED = "completed"
COMPENSATING = "compensating"
FAILED = "failed"
@dataclass
class SagaStep:
name: str
action_topic: str
action_payload: dict
compensation_topic: str
compensation_payload: dict
completed: bool = False
@dataclass
class OrderSaga:
saga_id: str = field(default_factory=lambda: str(uuid.uuid4()))
order_id: str = ""
status: SagaStatus = SagaStatus.RUNNING
current_step: int = 0
steps: list = field(default_factory=list)
def create_order_saga(order_data: dict) -> OrderSaga:
order_id = order_data["order_id"]
saga = OrderSaga(order_id=order_id)
saga.steps = [
SagaStep(
name="charge_payment",
action_topic="payment-commands",
action_payload={"command": "ChargePayment", "order_id": order_id,
"amount": order_data["total"], "customer_id": order_data["customer_id"]},
compensation_topic="payment-commands",
compensation_payload={"command": "RefundPayment", "order_id": order_id},
),
SagaStep(
name="reserve_inventory",
action_topic="inventory-commands",
action_payload={"command": "ReserveItems", "order_id": order_id,
"items": order_data["items"]},
compensation_topic="inventory-commands",
compensation_payload={"command": "ReleaseItems", "order_id": order_id,
"items": order_data["items"]},
),
SagaStep(
name="confirm_order",
action_topic="order-commands",
action_payload={"command": "ConfirmOrder", "order_id": order_id},
compensation_topic="order-commands",
compensation_payload={"command": "CancelOrder", "order_id": order_id},
),
]
save_saga_state(saga)
execute_next_step(saga)
return saga
def execute_next_step(saga: OrderSaga):
if saga.current_step >= len(saga.steps):
saga.status = SagaStatus.COMPLETED
save_saga_state(saga)
return
step = saga.steps[saga.current_step]
producer.send(step.action_topic, value=step.action_payload)
def handle_step_success(saga_id: str):
saga = load_saga_state(saga_id)
saga.steps[saga.current_step].completed = True
saga.current_step += 1
save_saga_state(saga)
execute_next_step(saga)
def handle_step_failure(saga_id: str, reason: str):
saga = load_saga_state(saga_id)
saga.status = SagaStatus.COMPENSATING
save_saga_state(saga)
compensate(saga)
def compensate(saga: OrderSaga):
# Walk backward through completed steps
for i in range(saga.current_step - 1, -1, -1):
step = saga.steps[i]
if step.completed:
producer.send(step.compensation_topic, value=step.compensation_payload)
saga.status = SagaStatus.FAILED
save_saga_state(saga)
Orchestration Trade-Offs
Advantages:
- The complete saga flow is visible in one place — the orchestrator defines every step, its compensation, and the order of execution
- Adding or reordering steps only requires changing the orchestrator, not multiple services
- The orchestrator stores the saga’s state, making it straightforward to query “what step is this order on?” for debugging
- Compensation logic is centralized and follows a predictable reverse-order pattern
Disadvantages:
- The orchestrator is a single point of coordination — if it fails, in-progress sagas stall until it recovers
- The orchestrator can accumulate too much business logic over time, becoming a “god service” that undermines service autonomy
- Services become somewhat coupled to the orchestrator’s command interface, although less so than with direct service-to-service calls
Choreography vs Orchestration: When to Choose Each
| Factor | Choreography | Orchestration |
|---|---|---|
| Number of steps | 2-4 steps | 4+ steps |
| Flow complexity | Linear, predictable | Branching, conditional |
| Team structure | Independent teams per service | Centralized platform team |
| Debugging | Harder (distributed tracing needed) | Easier (saga state in one place) |
| Adding steps | Modify multiple services | Modify orchestrator only |
| Coupling | Event-coupled (implicit) | Command-coupled (explicit) |
| Failure visibility | Requires aggregated logging | Built into orchestrator state |
For sagas with two or three steps and a linear flow, choreography is simpler and avoids the need for a dedicated orchestrator service. For sagas with four or more steps, conditional logic, or parallel branches, orchestration provides the structure needed to manage complexity. Most teams that start with choreography and later add steps eventually migrate to orchestration when debugging becomes too painful.
Designing Compensating Transactions
Compensation logic is the hardest part of the saga pattern to get right. A compensating transaction must semantically undo the effect of the original operation, but it cannot rely on database rollback because the original transaction already committed.
Compensation Is Not Always a Simple Reverse
Consider these examples where compensation requires careful thought:
Payment charge → Refund: Straightforward — issue a refund for the charged amount. However, refunds may take days to process, so the customer sees a temporary charge. Your compensation logic must handle this gracefully, potentially sending a notification explaining the refund timeline.
Inventory reservation → Release: Also straightforward — return the reserved items to available stock. But if another order reserved those same items between the original reservation and the compensation, releasing could create double-allocation. Use versioned inventory counts or optimistic locking to prevent this.
Email sent → ???: Some operations cannot be undone. Once a confirmation email is sent, you cannot unsend it. For irreversible operations, either move them to the last step of the saga (so they only execute after all reversible steps succeed) or design them to be idempotent and send a follow-up correction.
Idempotent Compensation
Compensating transactions must be idempotent because they may execute more than once. If the compensation message is delivered twice (due to network retries or at-least-once delivery), running the compensation twice should produce the same result as running it once.
def process_refund(order_id: str):
# Check if refund already processed (idempotency check)
existing_refund = db.execute(
"SELECT id FROM refunds WHERE order_id = %s", (order_id,)
).fetchone()
if existing_refund:
return existing_refund # Already refunded, skip
charge = db.execute(
"SELECT charge_id, amount FROM payments WHERE order_id = %s", (order_id,)
).fetchone()
if charge is None:
return None # No charge to refund
refund = payment_gateway.refund(charge["charge_id"], charge["amount"])
db.execute(
"INSERT INTO refunds (order_id, charge_id, amount, refund_id) VALUES (%s, %s, %s, %s)",
(order_id, charge["charge_id"], charge["amount"], refund["id"])
)
db.commit()
return refund
The idempotency check at the start ensures that repeated compensation calls do not issue duplicate refunds. This pattern should be applied to every compensating transaction in the saga.
Handling Saga Failures
Sagas introduce failure modes that do not exist in traditional transactions. Understanding these modes is essential for building resilient systems.
What If Compensation Fails?
If a compensating transaction itself fails, you have a partially compensated saga — some steps undone, others not. There are several strategies:
Retry with backoff: Most compensation failures are transient (network issues, temporary service unavailability). Retry the compensation with exponential backoff. Combined with circuit breaker patterns, retries avoid overwhelming a struggling service.
Dead letter queue: After exhausting retries, move the failed compensation to a dead letter queue for manual intervention. An operations team reviews and resolves stuck sagas.
Saga state persistence: Always persist the saga’s state to a database, including which steps completed and which compensations succeeded. This allows recovery after crashes — the orchestrator can resume compensation from where it left off.
def compensate_with_retry(saga: OrderSaga, max_retries: int = 3):
for i in range(saga.current_step - 1, -1, -1):
step = saga.steps[i]
if not step.completed:
continue
retries = 0
while retries < max_retries:
try:
producer.send(step.compensation_topic, value=step.compensation_payload)
step.compensated = True
save_saga_state(saga)
break
except Exception as e:
retries += 1
time.sleep(2 ** retries) # Exponential backoff
if not step.compensated:
# Move to dead letter queue for manual resolution
producer.send('saga-dead-letter', value={
"saga_id": saga.saga_id,
"failed_step": step.name,
"compensation_payload": step.compensation_payload,
})
Timeout Handling
Each saga step needs a timeout. If a service does not respond within the expected window, the orchestrator must decide whether to retry or compensate. Without timeouts, a saga can hang indefinitely waiting for a response from a crashed service.
Concurrent Saga Conflicts
Two sagas can conflict when they operate on the same resources. For example, two orders competing for the last item in stock might both reach the inventory reservation step simultaneously. Handle this with optimistic locking at the service level — the inventory service checks available stock with a version number and rejects reservations that would create negative stock.
Real-World Scenario: Implementing the Saga Pattern in a Travel Booking Platform
A travel booking platform allows customers to book a flight, hotel, and rental car in a single transaction. Each component is managed by a separate service: flights, hotels, and car rentals. The business requirement is that either all three bookings succeed or none of them stick — a customer should not end up with a flight and hotel but no rental car because the car service failed.
The team initially attempts choreography with three services publishing events. Within the first month, a subtle bug emerges: when the car rental service rejects a booking (no availability), the compensation events for the hotel and flight occasionally arrive out of order, leaving some bookings in an inconsistent state. Debugging requires correlating events across three Kafka topics with distributed tracing.
The team switches to an orchestration-based saga. The booking orchestrator defines the three steps (book flight → book hotel → book car) with compensating actions (cancel flight, cancel hotel, cancel car). The orchestrator persists its state to a PostgreSQL table, making it easy to query all in-progress sagas and identify stuck ones.
After the switch, a new edge case surfaces: the hotel cancellation API occasionally returns a 500 error during compensation, leaving sagas partially compensated. The team adds retry logic with exponential backoff (3 retries over 30 seconds) and a dead letter queue for sagas that exhaust retries. An operations dashboard monitors the dead letter queue, and a daily report flags sagas that require manual intervention. Over six months, fewer than 0.1% of sagas reach the dead letter queue, and the manual resolution process takes an average of 15 minutes per case.
The key architectural insight is that the saga pattern trades automatic rollback for explicit compensation, which is more work to implement but significantly more debuggable. After a booking failure, the orchestrator’s state table shows exactly which step failed, which compensations completed, and which are pending — information that would require correlating dozens of distributed logs in a choreography approach.
When to Use the Saga Pattern
- Business operations span multiple services that each own their own database
- Eventual consistency is acceptable — the system can tolerate brief windows where some services have committed and others have not yet compensated
- Operations involve steps that can be semantically reversed (refunds, cancellations, releases)
- Your microservices architecture has already adopted asynchronous communication via events or message queues
When NOT to Use the Saga Pattern
- A single database transaction can cover the entire operation — do not distribute what does not need distributing
- Strict real-time consistency is required (both services must reflect the change simultaneously) — sagas provide eventual consistency, not immediate consistency
- Compensating transactions are impossible or impractical for most steps (sending physical goods, making irreversible external API calls)
- Only two steps are involved — in many cases, a simple retry-or-fail approach is sufficient without the full saga machinery
Common Mistakes with the Saga Pattern
- Not making compensating transactions idempotent, leading to duplicate refunds or double-released inventory when compensation messages are retried
- Placing irreversible operations (sending emails, triggering external webhooks) early in the saga instead of last, making compensation impossible when later steps fail
- Ignoring the scenario where compensation itself fails — without retry logic and a dead letter queue, partially compensated sagas silently corrupt data
- Building choreography-based sagas with five or more steps, creating event chains that are nearly impossible to debug without centralized saga state
- Not persisting saga state, which means a service crash loses track of all in-progress sagas and their compensation progress
- Treating the saga pattern as a distributed transaction replacement rather than an eventual consistency pattern — sagas do not provide atomicity, they provide a structured way to handle partial failure
- Combining CQRS and event sourcing with sagas without clearly separating the event store from the saga state, leading to confusion about which events represent business facts versus saga coordination signals
Completing the Saga Pattern Overview
The saga pattern provides a structured approach to distributed transactions in microservices by replacing atomic rollback with explicit compensation. Choose choreography for simple, linear flows with two or three steps, and orchestration for complex flows where centralized visibility and control matter. In either approach, the quality of your compensation logic determines the system’s resilience — make every compensation idempotent, handle compensation failures with retries and dead letter queues, and persist saga state so that recovery after crashes is possible.
Start by identifying the business operations in your system that currently span multiple services without any consistency mechanism. Those are the operations that benefit most from the saga pattern. Build the orchestrator, define your compensating transactions, and invest in monitoring that makes stuck sagas visible before they become customer complaints.