Fine-Tuning Unsloth: Fine-Tune LLMs 12x Faster on a Single GPU If you have a model that keeps getting the same domain-specific task wrong and prompting isn’t fixing it, fine-tuning is...
Local & Open-Source LLMs LLM Quantization: GGUF, AWQ, GPTQ, and When to Use If you have ever tried to run a capable open model on your own hardware, you have hit the wall:...
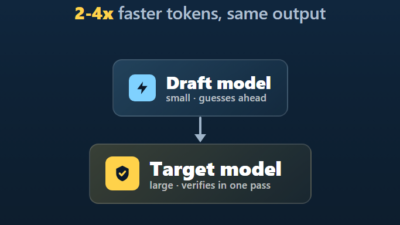
Local & Open-Source LLMs Speculative Decoding: 2-4x Faster Local LLM Inference If you run language models on your own hardware, you already know the bottleneck: tokens come out one at a...
Local & Open-Source LLMs 70B Models on a Mac Mini: A $1,600 Local LLM Setup If you want a private, always-on machine that can run a 70-billion-parameter model without a noisy GPU rig or a...
Local & Open-Source LLMs Llama.cpp: Running Quantized LLMs on CPU-Only Machines If you want to run a capable language model on a laptop or a cheap cloud box with no GPU,...
Local & Open-Source LLMs vLLM: Fast, Self-Hosted LLM Serving With GPUs If you have outgrown hosted APIs and want to run open models like Llama or Qwen on your own hardware,...
Local & Open-Source LLMs LM Studio: Run and Test Local LLMs With a GUI If you want to run open models on your own machine but the command line feels like friction, LM Studio...
Local & Open-Source LLMs Ollama: Running Local LLMs on Your Laptop in 5 Minutes If you want to experiment with Ollama local LLMs without sending a single token to a cloud provider, this guide...
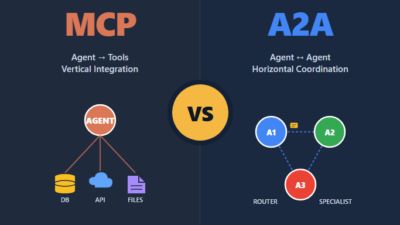
AI Agents & Frameworks A2A Protocol vs MCP: Which Agent Standard to Adopt If you are building AI agents in production, you have probably hit the question of which open protocol to standardize...